
先跑通一个最小 LangChain Agent,再回头看它的设计哲学、生态关系和为什么它不是简单的模型调用封装。
这篇是整条学习线的起点文章。它保留了"先搭一个最小 Agent 看全貌"的视角,但我把它放在真正进入各组件之前,让它承担"先看全景图,再拆零件"的作用。
1. 介绍与安装
LangChain 是一个用于构建LLM应用的开源开发框架,有Python和Java两种包,注重组合和模块化。利用LangChain,可以创造完全自定义的agents和LLM应用,可以在不到10行代码内连接到OpenAI、Anthropic、Google等。
关于它和LangGraph、Deep Agents的区别,也给的很详细,大概就是Deep Agents开箱即用;LangChain 代理构建在 LangGraph 之上,以提供持久执行、流媒体、人工干预、持久性等功能。基本使用 LangChain 代理不需要了解 LangGraph,只要需要深度自定义的时候才用LangGraph。
我们基于LangChain的官方文档进行学习。
先安装一下,然后LangChain说自己对许多LLM有融合,这些融合在独立的包中,所以我们安装一下对OpenAI的支持。
pip install -U langchainpip install -U langchain-openai2. 获得AI coding assistant
官网提供了一个LangChain Docs MCP server来帮助你的agent获取最新文档,并提供一个LangChain Skills来帮你提高agent在LangChain ecosystem的表现。我正好有一个codex账号,平时用agent插件辅助编码,现在就接入试试。
首先按照官网提供的MCP地址,给codex配置,然后用prompt测试连接:
可以看到,已经成功连接到了LangChain Docs的API。
然后,我们依旧按照官网地址,给codex提供LangChain Skills。这个skill可以帮助搭建LangChain、LangGraph和Deep Agents。
npx是Node.js生态里的一个通用命令执行工具,用于直接运行npm包提供的命令。所谓Node.js是JavaScript程序的运行环境,npx skills可以运行一个叫skills的Node.js CLI工具。至于为什么不继续发布到Python的PyPI,主要还是因为JS还有一些自己的好处,我问了问AI总结如下:

总之,只要"support the Agent Skills specification",也就是说agent支持标准的Agent规范,就可以用命令添加。Agent Skills的介绍如下:Agent Skills文档,这里按下不表,之后进行学习,不然就跑偏太远了。
npx skills add langchain-ai/langchain-skills --skill '*' --yes这个命令实际上干了两件事:
- 临时拉取工具: npx 去网上临时下载了一个名叫 skills 的执行工具(这个工具被塞进了 ~/.npm/_npx 里)。
- 执行添加动作: 这个 skills 工具运行了 add 命令,把 langchain-skills 添加到了你的当前工作目录下。
我们看看目录,果然多了一堆东西:
总之,这个先这样,现在我们是把skills放在了当前目录下,在这里使用agent可以让它自己去读取。但是其实也可以放~/.agents/skills/一劳永逸,用这样的命令:
npx skills add langchain-ai/langchain-skills --skill '*' --agent codex -g执行完这条,还默认给我装了Find Skills的Skill,我们检查文件如下:

里面有点像说明书,暂时不展开,之后应该会细看。
3. 搭建一个基础Agent
官网给的最小实例,好像是默认你装了OpenAI兼容包,设置了OpenAI的key,而且走官方路径。我们走的中转,环境变量也是在.env中,因此我们自己要设置一下:
Python3
点击展开代码
展开代码
我们来看看原始输出的结果:
{ "messages": [ { "type": "HumanMessage", "content": "what is the weather in sf", "additional_kwargs": {}, "response_metadata": {}, "id": "11c974bc-3204-4e15-9391-40db1cd6c982" }, { "type": "AIMessage", "content": "", "additional_kwargs": { "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 16, "prompt_tokens": 56, "total_tokens": 72, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_provider": "openai", "model_name": "gpt-4o-mini-2024-07-18", "system_fingerprint": "fp_eb37e061ec", "id": "chatcmpl-DNMHzlR2RTmob84VvtgxHEcA2jWwF", "finish_reason": "tool_calls", "logprobs": null }, "id": "lc_run--019d2608-a56b-7991-84f5-3a40addac2bb-0", "tool_calls": [ { "name": "get_weather", "args": { "city": "San Francisco" }, "id": "call_GHZls5pzrZTFanydz2VJANUb", "type": "tool_call" } ], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 56, "output_tokens": 16, "total_tokens": 72, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } }, { "type": "ToolMessage", "content": "It's always sunny in San Francisco!", "name": "get_weather", "id": "f84e1e0b-bf8b-4dcd-bdc2-cd9d40a7c1b2", "tool_call_id": "call_GHZls5pzrZTFanydz2VJANUb" }, // 下面就是message列表的最后一项,AIMessage { "type": "AIMessage", "content": "The weather in San Francisco is currently sunny!", "additional_kwargs": { "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 11, "prompt_tokens": 86, "total_tokens": 97, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_provider": "openai", "model_name": "gpt-4o-mini-2024-07-18", "system_fingerprint": "fp_eb37e061ec", "id": "chatcmpl-DNMI1dEwEqVRaNAX2FI8sUJXZl9nW", "service_tier": "default", "finish_reason": "stop", "logprobs": null }, "id": "lc_run--019d2608-ae45-7a23-a3d7-79389811c5fc-0", "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 86, "output_tokens": 11, "total_tokens": 97, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } } ]}这就是回复体啦,可以看到超级长一串。我们可以将其看为四部分:用户问题、模型判断是否调用工具、工具执行结果、模型基于工具结果的最终回答。我们这里是用了一个假工具告诉Agent总是晴天。
如果我们只想抽取回复,可以拿result["messages"][-1].content来打印,就拿到了AIMessage的content:"The weather in San Francisco is currently sunny!"
4. 建立一个真实agent
按照官网的build步骤,我们开始构建,这里同样构造一个天气agent(伪)。
(1) 定义prompt
我们需要一段系统提示词,用于定义agent的角色和行为,需要保持specific和actionable。
# Step1 Defines the system promptSYSTEM_PROMPT = """以下英文提示词,但是请用中文回答。You are an expert weather forecaster, who speaks in puns.
You have access to two tools:
- get_weather_for_location: use this to get the weather for a specific location- get_user_location: use this to get the user's location
If a user asks you for the weather, make sure you know the location. If you can tell from the question that they mean wherever they are, use the get_user_location tool to find their location."""(2) 创建工具
工具允许模型通过调用您定义的函数与外部系统交互。工具可以依赖于运行时上下文(runtiem context),并与agent内存进行交互。
@tool是将一个Python函数注册成LangChain可调用的工具,并读取工具名、参数、描述(docstring说明文档 ,也就是函数上面那一段三引号内部内容)、返回值。@dataclass则是python标准库中的装饰器,表达"只装数据的类",这样可以自动生成很多样板代码,比如__init__,你可以直接写ctx = Context(user_id="1")。
。
官方文档:工具应有详细文档:它们的名称、描述和参数名称成为模型提示的一部分。LangChain 的 @tool 装饰器添加元数据,并通过 ToolRuntime 参数启用运行时注入。请在工具指南中了解更多。
Python3
点击展开代码
展开代码
(3) 配置模型
官网给出的方法,是通用对话模型的创建方法,它通过provider适配层+模型名规则识别,来走自动集成的配置。更推荐这么写,方便随时更换模型。我们在模型前面注明provider(不注明走自动判断)。
Python3
点击展开代码
展开代码
(4) 定义回复格式
这是可选项,可以定义模型回复的格式。这里也明确说明了,除了dataclass,也可以用Pydantic来定义,LangChain只是需要一个结构化的schema。方便复习,所以我们之类就用Pydantic。
另外,其实所有dataclass都可以直接换成pydantic,比如Context。
Python3
点击展开代码
展开代码
(5) 添加记忆
为agent添加记忆,以在交互之间保持状态。这使代理能够记住先前的对话和上下文。之后会专门来学习这个记忆模块,现在只做简单了解,把这个InMemorySaver传给Agent。
Python3
点击展开代码
展开代码
(6) 创建和运行agent
把前面定义过的一些参数,传进create_agent里面,创建出agent。然后,再定义一个config,调用agent的invoke,传入对话、config和Context,就可以获得回答了。
Python3
点击展开代码
展开代码
(7) 分析结果
先看一下原始结果是啥样的,我们把直接print(response)整理成了json结果,大概是这样的:
{ "messages": [ { "type": "HumanMessage", "content": "what is the weather outside?", "additional_kwargs": {}, "response_metadata": {}, "id": "a0514473-c615-4362-826e-92ec42a63884" }, { "type": "AIMessage", "content": "", "additional_kwargs": { "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 12, "prompt_tokens": 224, "total_tokens": 236, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_provider": "openai", "model_name": "gpt-4o-mini-2024-07-18", "system_fingerprint": "fp_eb37e061ec", "id": "chatcmpl-DNYJbb2YC3bGBabU4cMChBtS8XzEB", "finish_reason": "tool_calls", "logprobs": null }, "id": "lc_run--019d28c9-ddd4-7f83-9f16-b9a82cc51a0e-0", "tool_calls": [ { "name": "get_user_location", "args": {}, "id": "call_Yc265lCmfCTiSFb0ywzfbZeX", "type": "tool_call" } ], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 224, "output_tokens": 12, "total_tokens": 236, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } }, { "type": "ToolMessage", "content": "Shanghai", "name": "get_user_location", "id": "6eb3e154-d329-4497-aa2b-e6ea8803c91b", "tool_call_id": "call_Yc265lCmfCTiSFb0ywzfbZeX" }, { "type": "AIMessage", "content": "", "additional_kwargs": { "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 17, "prompt_tokens": 244, "total_tokens": 261, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_provider": "openai", "model_name": "gpt-4o-mini", "system_fingerprint": "fp_eb37e061ec", "id": "chatcmpl-DNYJel8PrtJkiYfONkB1Le1TPWQuS", "finish_reason": "tool_calls", "logprobs": null }, "id": "lc_run--019d28ca-1321-7231-a3b3-0ca73eb8e4a8-0", "tool_calls": [ { "name": "get_weather_for_location", "args": { "city": "Shanghai" }, "id": "call_DuMTODUFSuEZyeC6feJl1q8b", "type": "tool_call" } ], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 244, "output_tokens": 17, "total_tokens": 261, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } }, { "type": "ToolMessage", "content": "It's always rainy in Shanghai!", "name": "get_weather_for_location", "id": "131320f4-c2c5-4bba-b153-cfdc1a3d3a38", "tool_call_id": "call_DuMTODUFSuEZyeC6feJl1q8b" }, { "type": "AIMessage", "content": "", "additional_kwargs": { "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 46, "prompt_tokens": 277, "total_tokens": 323, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_provider": "openai", "model_name": "gpt-4o-mini-2024-07-18", "system_fingerprint": "fp_eb37e061ec", "id": "chatcmpl-DNYJfkI8eMkpScdEUDH2VweZJ8j8J", "finish_reason": "tool_calls", "logprobs": null }, "id": "lc_run--019d28ca-1b81-7e02-b17a-7cc074ac7645-0", "tool_calls": [ { "name": "ResponseFormat", "args": { "weather_conditions": "多雨", "punny_response": "上海的天气真是让人\"水\"深火热,今天又是个\"下雨天\"!" }, "id": "call_PzZ5A1CewBlCZFBO60f7AeXs", "type": "tool_call" } ], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 277, "output_tokens": 46, "total_tokens": 323, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } }, { "type": "ToolMessage", "content": "Returning structured response: punny_response='上海的天气真是让人\"水\"深火热,今天又是个\"下雨天\"!' weather_conditions='多雨'", "name": "ResponseFormat", "id": "dbdac10f-0c98-40d7-b688-1f69908b1136", "tool_call_id": "call_PzZ5A1CewBlCZFBO60f7AeXs" }, { "type": "HumanMessage", "content": "thank you!", "additional_kwargs": {}, "response_metadata": {}, "id": "5b17ed89-3b4e-423f-a0f1-44fac7029215" }, { "type": "AIMessage", "content": "", "additional_kwargs": { "refusal": null }, "response_metadata": { "token_usage": { "completion_tokens": 45, "prompt_tokens": 375, "total_tokens": 420, "completion_tokens_details": { "accepted_prediction_tokens": 0, "audio_tokens": 0, "reasoning_tokens": 0, "rejected_prediction_tokens": 0 }, "prompt_tokens_details": { "audio_tokens": 0, "cached_tokens": 0 } }, "model_provider": "openai", "model_name": "gpt-4o-mini", "system_fingerprint": "fp_eb37e061ec", "id": "chatcmpl-DNYJhKUMQBmPsNDE56FyIE4yZ1fPY", "finish_reason": "tool_calls", "logprobs": null }, "id": "lc_run--019d28ca-21e5-7812-86af-c7556b1cd64c-0", "tool_calls": [ { "name": "ResponseFormat", "args": { "punny_response": "不客气,\"天气\"如人心,\"风\"云变幻!希望你有个\"晴\"朗的一天!" }, "id": "call_OjxJ1IqfxM4zzzABiNUTwE1E", "type": "tool_call" } ], "invalid_tool_calls": [], "usage_metadata": { "input_tokens": 375, "output_tokens": 45, "total_tokens": 420, "input_token_details": { "audio": 0, "cache_read": 0 }, "output_token_details": { "audio": 0, "reasoning": 0 } } }, { "type": "ToolMessage", "content": "Returning structured response: punny_response='不客气,\"天气\"如人心,\"风\"云变幻!希望你有个\"晴\"朗的一天!' weather_conditions=None", "name": "ResponseFormat", "id": "0ed7a498-f2ae-4bee-8531-77181a3c51ee", "tool_call_id": "call_OjxJ1IqfxM4zzzABiNUTwE1E" } ], "structured_response": { "type": "ResponseFormat", "punny_response": "不客气,\"天气\"如人心,\"风\"云变幻!希望你有个\"晴\"朗的一天!", "weather_conditions": null }}好,其实一路看下来还是比较清晰的结果。注意几个点:
- 因为写了
response_format=ToolStrategy(ResponseFormat),所以LangChain为了拿到结构化输出,把这个schema包装成了类似工具调用的内部步骤。 - 打印response不只是本轮新增内容,而是整个thread的当前状态。我们发送了一个问天气的消息,又发送了一个thank you,最后会打印整个线程所有对话。
- ResponseFormat里面的description,不仅仅是给人看的主食,也参与到模型结构化输出约束中。它跟system_prompt的起效层级不一样,约束力没那么强硬,算是进一步引导。
当然,我们可以指定字段,防止输出这么一长串有点傻的东西。我们用response['structured_response']
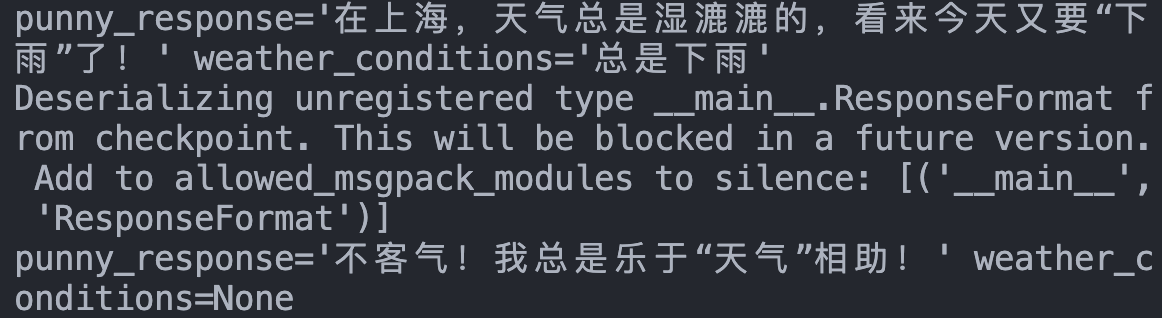
注意到这里其实有个警告,"正在从 checkpoint 反序列化一个未注册的类型 __main__.ResponseFormat。",未来的版本或许不允许这样用。意思是如果确认这个类型是安全且允许回复,要加入 allowed_msgpack_modules 白名单。
消除这个警告的方法也很简单,将ResponseFormat放大单独的模块中,比如就叫schemas.py,然后再导包进来,这样就不是__main__.ResponseFormat而是schemas.ResponseFormat了。
5. 设计哲学
在此界面提了一下,我这里简单概述一下。
这一页不是在教具体 API 怎么写,而是在解释 LangChain 想成为什么样的框架,以及它为什么这样设计。
官方的核心意思可以概括为:LangChain 想成为"构建带上下文能力和推理能力的应用的最简单方式"。这里说的不是只调用一次模型,而是构建完整应用,让模型能读上下文、调工具、输出结构化结果,并在真实项目中持续运行。
(1) 从简单开始,但可以扩展到复杂应用
LangChain 希望开发者一开始就能用很少的代码搭起一个能运行的 agent 或 LLM 应用,而不是先学习大量底层细节。但它又不想只适合 demo,因此同一套框架要能继续扩展到更复杂的生产场景。
我的理解是:
- 入门时可以先用高层封装快速起步
- 后面需求变复杂时,不需要整套推倒重来
- 可以逐步加入工具、结构化输出、记忆、检索和工作流
(2) 提供高层抽象,但不要把开发者困在黑盒里
LangChain 的哲学不是"把一切都藏起来",而是默认给你高层接口来提升开发效率,同时保留足够的可控性。
所以它的思路通常是:
- 常见任务给出简单接口
- 复杂需求允许向下深入
- 当高层抽象不够时,可以转向 LangGraph 做更细粒度的编排
也就是说,LangChain 追求的是"默认简单,但不牺牲控制力"。
(3) 设计重点是现实中的 agent 应用
LangChain 关注的不是孤立的一次 prompt 调用,而是一个真实 AI 应用从输入到输出的完整过程。例如:
- 如何连接不同模型提供商
- 如何让模型调用工具
- 如何管理上下文
- 如何拿到结构化输出
- 如何调试和观测 agent 的行为
因此它很多设计都围绕"让 agent 应用真正可用"展开,而不是只服务于演示性质的 prompt 实验。
(4) 尽量与具体模型提供商解耦
LangChain 希望应用逻辑不要被某一家模型提供商强绑定。也就是说,如果底层模型从 OpenAI 换成 Anthropic、Google 等,开发者最好还能保留大部分上层逻辑。
这也是为什么文档里会不断强调:
- 统一的模型初始化方式
- 统一的消息接口
- 统一的工具调用模式
它想减少"换模型就重写程序"的成本。
(5) 重视生产可用性,而不只是能跑
LangChain 的目标不是"代码能执行一次就行",而是希望它能走向真实项目。所以它会特别重视:
- tracing
- observability
- debugging
- structured output
- 与 LangSmith / LangGraph 的协作
也就是说,一个应用不仅要能回答问题,还应该能被追踪、分析、调试和维护。
(6) LangChain 和 LangGraph 的关系
从设计哲学上看,LangChain 更偏向"让构建 agent 更容易",而 LangGraph 更偏向"提供底层运行时和编排能力"。
可以这样理解:
- LangChain:高层、上手快、常见场景更省心
- LangGraph:底层、可控性更强、适合复杂流程
所以官方常见的建议是:先从 LangChain 入门,当需求需要更复杂的控制时,再下沉到 LangGraph。
(7) 我的总结
这页 Philosophy 本质上是在告诉读者:
- LangChain 不只是模型调用封装
- 它更像一个 AI 应用框架
- 它强调易用性,但不想把开发者锁死在黑盒里
- 它的很多抽象,都是为了让应用可以从 demo 平滑过渡到真实项目
专题阅读
LangChain
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。