
把前面的 RAG 基础真正串起来,做一个最小可运行的 Naive-RAG demo:文档切分、向量入库、本地 QA、FastAPI 服务与 Docker 化。
这一篇可以看作前面 1 到 6 篇的第一次汇总练习。目标不是做一个"很聪明"的系统,而是先把最小闭环打通:文档 -> 切分 -> 嵌入 -> Milvus -> 检索 -> 回答 -> API 服务。
Naive-RAG 实战
1. 设想和路线
我们假设已经有LangChain的基础,RAG理论,Milvus入门的学习了,现在想要做一个简单的demo,目标是整合FastAPI + LangChain,做一个Naive-RAG端到端回答系统,然后用Docker打包发布,从而将部分学习的东西先变成整体,化为内功。
什么是Naive-RAG?简单来说,这就是最原始、最直接的RAG生成方式,分为"检索+生成"两步走。
我准备直接把我的强化学习文档作为检索来源,上传。
AI给我的最小交付建议:
- POST /ingest:上传 pdf/md/txt,完成切块、embedding、入库
- POST /ask:输入问题,返回答案、命中文档片段、来源
- GET /health:健康检查
- docker-compose up 能一键启动
- 准备一份 20~30 条的小评测集
并且评估不能靠"感觉答得不错",要看4件事:
- 检索命中率:答案所在片段有没有进 top-k
- 答案正确性:回答是否接近参考答案
- Groundedness:回答是否被检索到的上下文支持
- 延迟/成本:一次问答耗时和 token 开销
回到我的资料,我准备用强化学习入门时候的笔记(文件是markdown),特点是有大量的图片,但是文字量本身不大,标题层级明显,章节结构不错。麻烦点在于图片里有关键知识,我决定预处理把图片先换成AI生成的图片描述,然后再处理纯文本的md。
第一阶段应该把重点放在"让回答严格受笔记约束"。主要是因为,RL算是LLM本来就很熟的领域,如果不限制就直接用自己的知识答了,所以我们第一版要做成grounded_only的设计(以后可以拓展)。
2. 文档入库
我必须先实现好文档的切分和入库。我采用在项目文件下写一个.env的方法,存入我的三方数据库和key,还有milvus相关配置。
经过边写边和AI沟通考虑,我将先写下处理单个文档的脚本markdown_splitter.py,它对外暴露split_markdown_file,返回一个list[Document](Document是langchain.core里面的一个类,用于处理文件,后续RAG大多依赖于这个)。对文档我们采用两级切分,首先按markdown语法切分,然后再检索其中过长的块,进行第二次Recursive切分。代码如下:
Python3
点击展开代码
展开代码

3. chunk加载进库
前面我们已经切分完毕,现在写一个docs_to_milvus.py函数,负责创建需要的Collection并且将chunk调整成适合schema的字典,插入Collection。
Python3
点击展开代码
展开代码
4. 本地QA
为了先看看Naive-RAG是否已经形成了完整的通路,我们现在本地用聊天模型试试效果。代码qa_pipeline.py和运行结果如下:
Python3
点击展开代码
展开代码

5. FastAPI
我们在Naive-RAG下面再创建一个文件夹叫做app,并存放逻辑,将其做成一个最小但是像项目的结构。
原来的 qa_pipeline.py -> 被拆成 rag_service.py + schemas.py + main.py
原来脚本里的 os.environ.get(…) -> 收到 config.py
原来的 if name == "main": -> 变成了 FastAPI 的 /ask 路由
原来"打印字符串结果" -> 变成结构化 API 响应
这样使得结果更适应FastAPI。
一个一个来,我们先看看app/rag_service.py,它是将之前的所有流程都封装了进去,对外暴露一个RAGService类。当然,逻辑和前面都是一样。
Python3
点击展开代码
展开代码
然后是app/config.py,这里直接对外暴露一个settings实例,以后直接调用即可。我们把默认设置和环境变量都在这里读取了先。
Python3
点击展开代码
展开代码
我们可以看到,这里用到了之前都没有用过的from pydantic_settings import BaseSettings, SettingsConfigDict。其实这属于专门用来写配置类的Pydantic基类。下面的语法,就是给BaseSettings配置行为用的,他告诉BaseSettings去哪个文件找配置,然后按什么编码读文件,遇到没有声明过的环境变量怎么处理。
model_config = SettingsConfigDict( env_file=env_path, env_file_encoding="utf-8", extra="ignore",)所以我们在Settings类中定义了milvus_url等,并把validation_alias设置成了MILVUS_URL,跟环境变量里面写的对上了。
然后,因为我们要做的FastAPI接口了,用户不再是"终端里的一句话",而是一个HTTP请求。所以程序必须知道这个请求体的规范,这就要请app/schemas.py登场了:
Python3
点击展开代码
展开代码
里面定义了四个类。AskRequest是定义了/ask请求应该接受什么样的请求体,包括question用min_length = 1表示必填,k可选(我们在config中已经定义默认值为4了,不需要用户一定要每次请求提供);SourceItem适用于定义单条来源信息的标准结构,因为每次回答我们还会返回一个来源列表,包含片段编号、标题、分数;AskResponse用于定义/ask最终返回给调用方的数据结构,包含答案、是否覆盖、来源列表;HealthResponse就是给/health用的。
其实可以返回的时候全写字典,但是这样写对FastAPI 文档自动生成更友好,而且更容易维护。我们可以看到,rag_service.py就引用了这些类来作为信息的包装。
最后,我们来看看app/main.py:
Python3
点击展开代码
展开代码
这个就是FastAPI的主入口,我们已经知道config.py 是配置入口,schemas.py 是接口协议,rag_service.py 是真正干活的业务层,那main.py的指责就很单纯了,它负责把HTTP请求接进来,再转交给RAGService。
先导入全局配置settings,导入fastapi的请求和对象,导入业务类RAGService,导入schemas中的各种规范类。
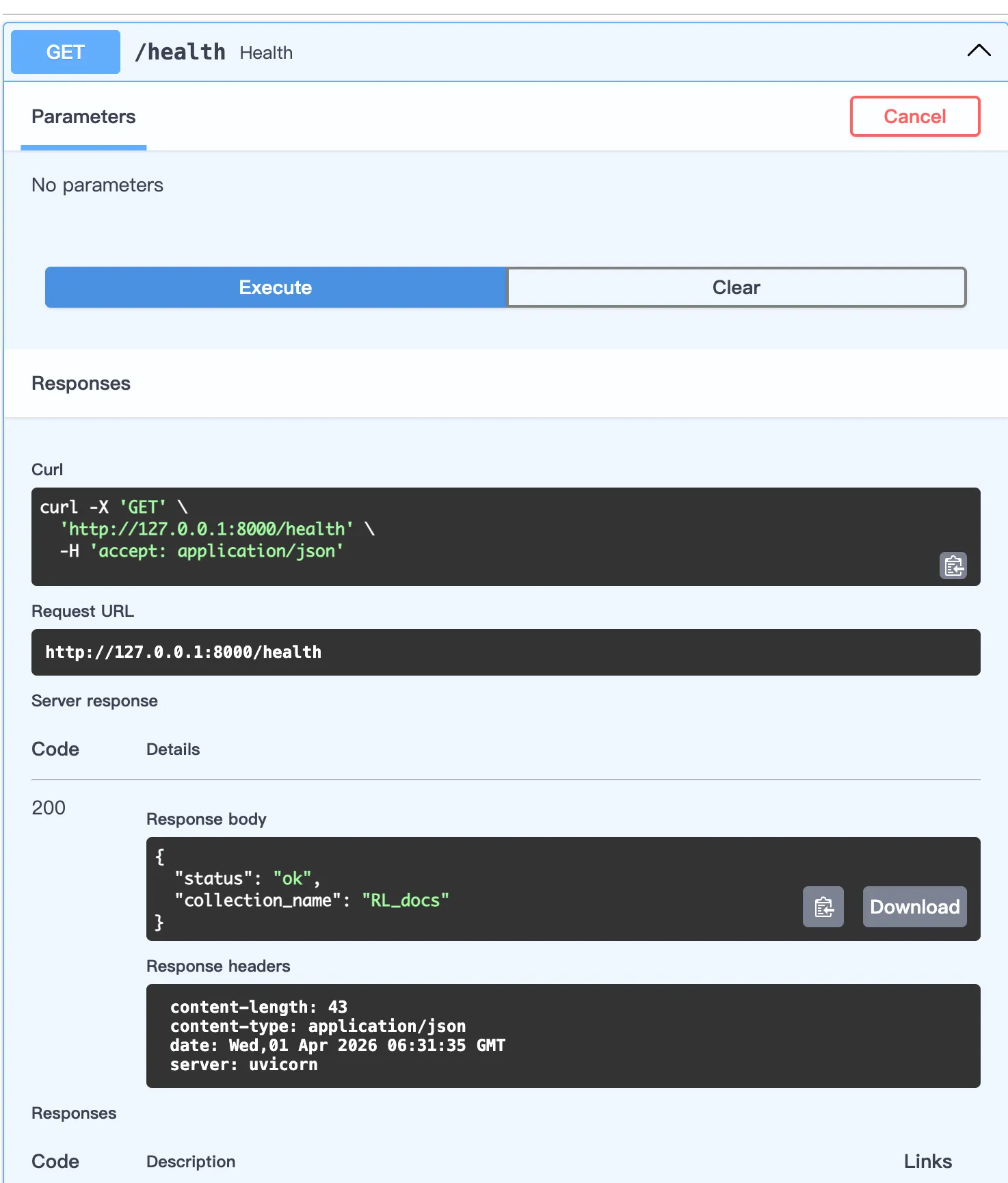
然后,用lifespan初始化一个全局可复用的RAGService,传入settings参数,生成并挂载应用级别全局对象app.state.rag_service。然后用yield表示初始化完成,可以开始处理请求(注意后面做FastAPI实例的时候传入一下lifespan)。然后,定义了一个健康检查路由/health,先用GET /health看看服务是否健康,并告诉连接的是哪个collection。
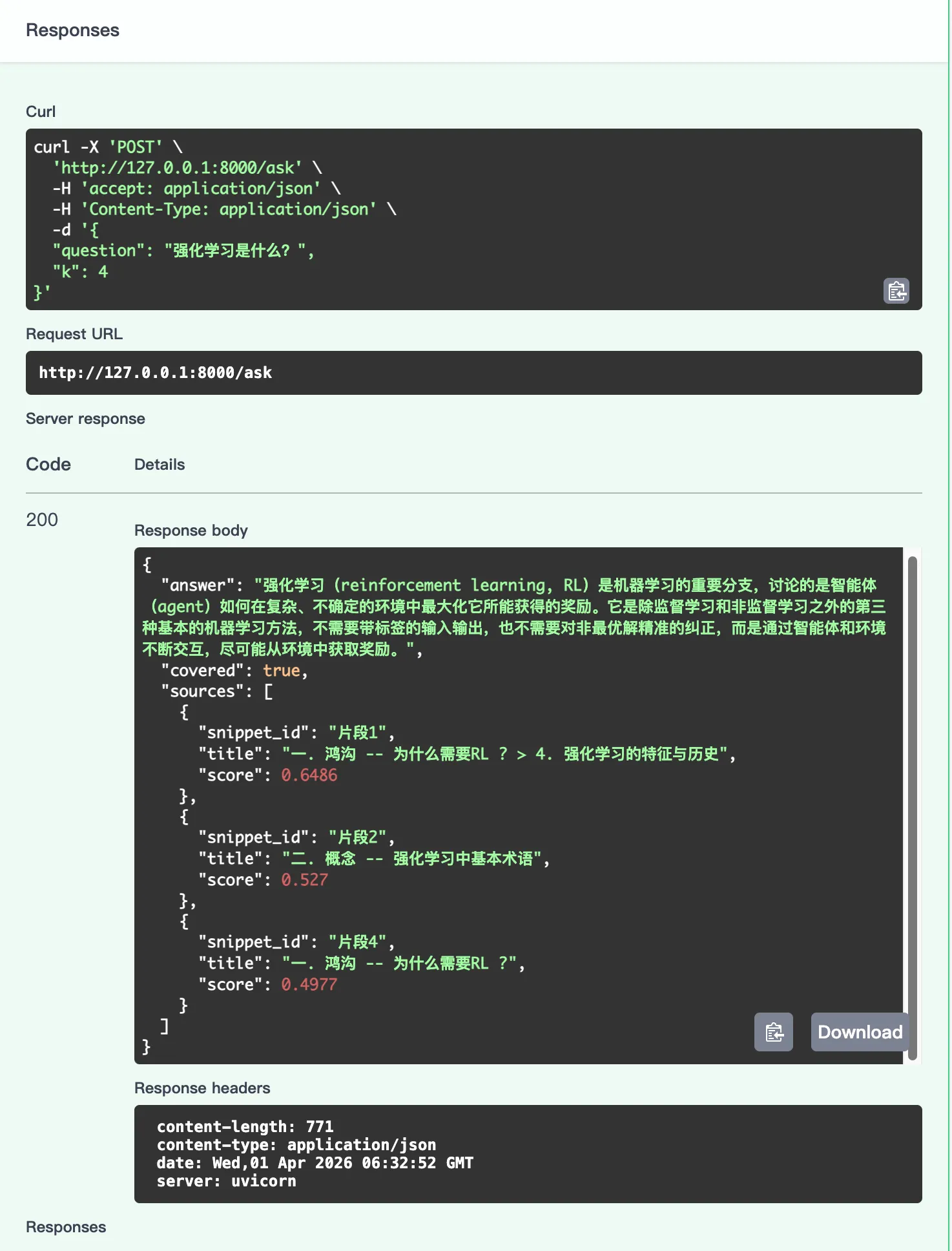
然后,就是重头戏/ask接口了,定义了一个用于POST /ask 的,按照AskRequest包装起来,调用RAGService的answer,返回。
使用uvicorn app.main:app --reload启动之后,我们直接访问文档页,http://127.0.0.1:8000/docs#/,发现就可以看到自己定义的接口和规范:
执行健康检查,状态没问题,并显示出Collection名:
执行ask,查看RAG链路是否正确:
再看一眼我们定义的Schemas:

不过另外要提醒一下,glob + 读文件 + 切分 + 入库依旧在docs_to_milvus.py里面,没有塞进FastAPI在线请求,不然会很重耦合(并且每次启动都要嵌入文件,很慢)。
6. Docker打包
在打包发布之前,我们先整理依赖。这个项目比较简单,可以记住用过哪些依赖。以后的开发最后都单独建一个环境,然后把用到的包都给freeze一下。
fastapi==0.135.1uvicorn==0.42.0pydantic==2.12.5pydantic-settings==2.13.1langchain==1.2.13langchain-openai==1.1.12pymilvus==2.6.11python-dotenv==1.2.2然后,我们写Dockerfile如下:
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1 \ PYTHONUNBUFFERED=1
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir --upgrade pip \ && pip install --no-cache-dir -r requirements.txt
COPY app ./app
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]这版本的Dockerfile,将FastAPI问答服务包装成一个可运行镜像,打包app在线服务层(不包含离线注入脚本)。以一个已经装好 Python 3.11 的轻量 Linux 镜像作为基础,ENV PYTHONDONTWRITEBYTECODE=1 \ PYTHONUNBUFFERED=1代表不生产.pyc字节码缓存文件;PYTHONUNBUFFERED=1让python日志立刻输出;WORKDIR /app表示设置容器内的工作目录;COPY requirements.txt .是把requirements.txt复制到/app下;然后我们RUN一下环境依赖(记得加--no-cache-dir );COPY app ./app表示将本地的app/目录复制到容器里/app/app,这里没有复制docs和scripts;EXPOSE 8000表好似暴露容器的8000端口到宿主机,最后用CMD命令表示启动的命令。
现在,来到项目根目录,就可以用docker build -t owen571/naive-rag:0.1.0 .根据file文件构建起来一个镜像。
然后我们用docker run --rm -p 8000:8000 --env-file .env owen571/naive-rag:0.1.0来确认是否构建镜像成功即可。这里还有几个坑:
- 不能继续使用localhost,要是用
MILVUS_URL=http://host.docker.internal:19530这样的说法。 - 环境变量不需要引号,等号两边不能有空格。docker的-env-file检查比load_dotenv严格一点
如下启动完成了(由于没写名字,被临时取名了)

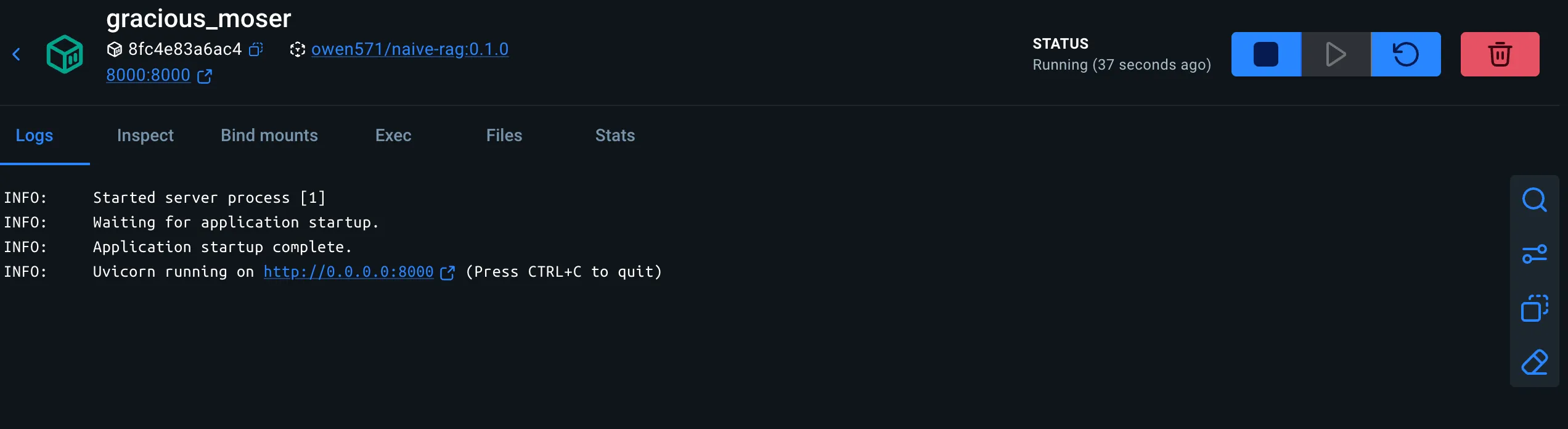
启动之后,我们会发现功能都是正常的。
7. 发布
登录时候,直接推送如下:
docker push owen571/naive-rag:0.1.0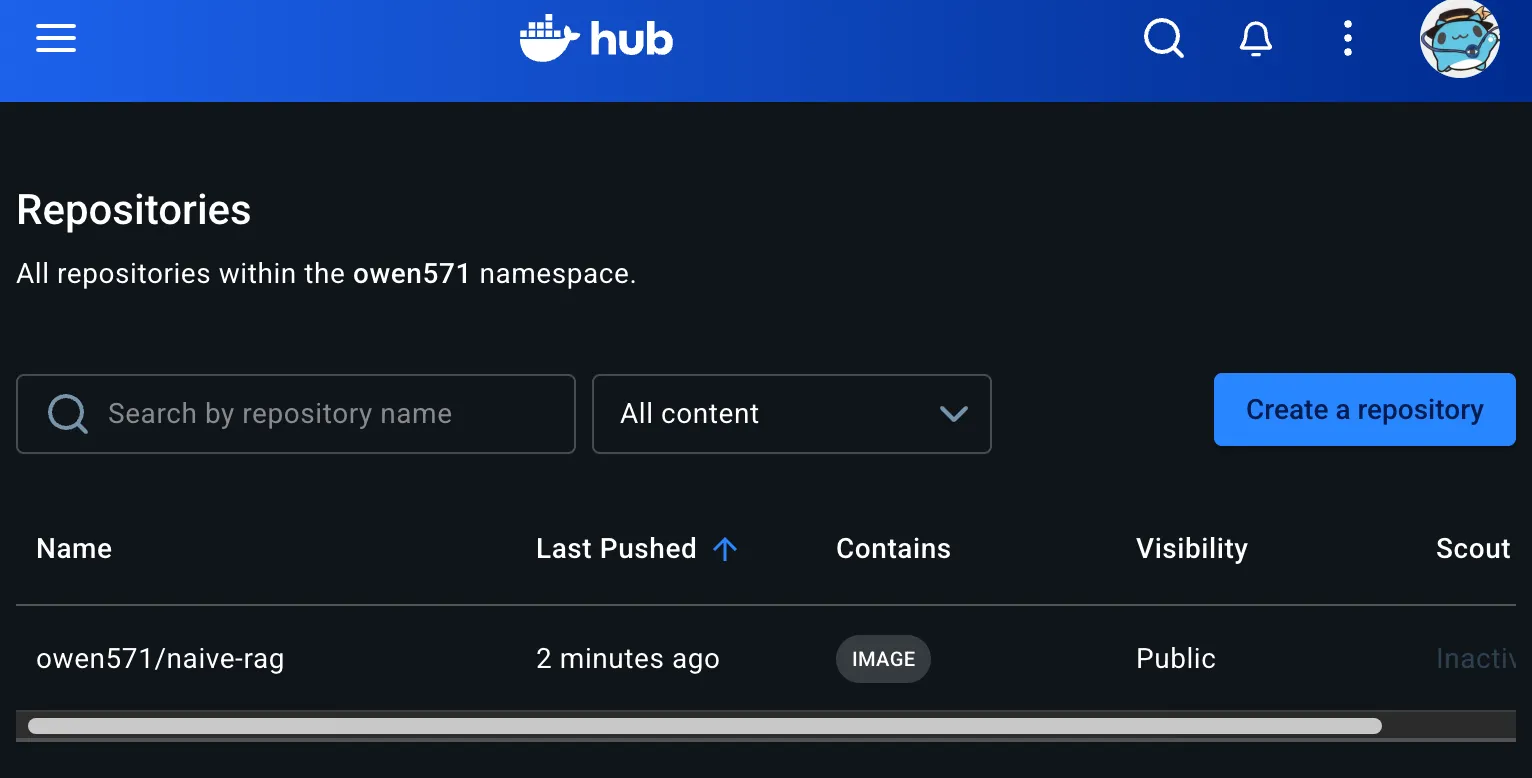
专题阅读
RAG
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。