
当知识源不再只是纯文本时,RAG 不能只做语义匹配,还要学会把自然语言问题翻成过滤器、Cypher 或 SQL。
到这里,检索已经不只是"把一句问题编码成向量再去搜文本"。如果底层数据源本身带结构,查询构建的关键就在于先把自然语言翻译成合适的查询表达式。
RAG - 查询创建
1. 介绍
前面大多学习从非结构化的数据中检索信息,但是实际应用中,我们常常需要处理更加复杂和多样化的数据,包括结构化数据(如SQL数据库)、半结构化数据(如带有元数据的文档)以及图数据。用户的查询也可能不仅仅是简单的语义匹配,而是包含复杂的过滤条件、聚合操作或关系查询。
查询构建(Query Construction)正是应对这一挑战的关键技术。它利用大语言模型(LLM)的强大理解能力,将用户的自然语言查询"翻译"成针对特定数据源的结构化查询语言或带有过滤条件的请求。这使得RAG系统能够无缝地连接和利用各种类型的数据,从而极大地扩展了其应用场景和能力。
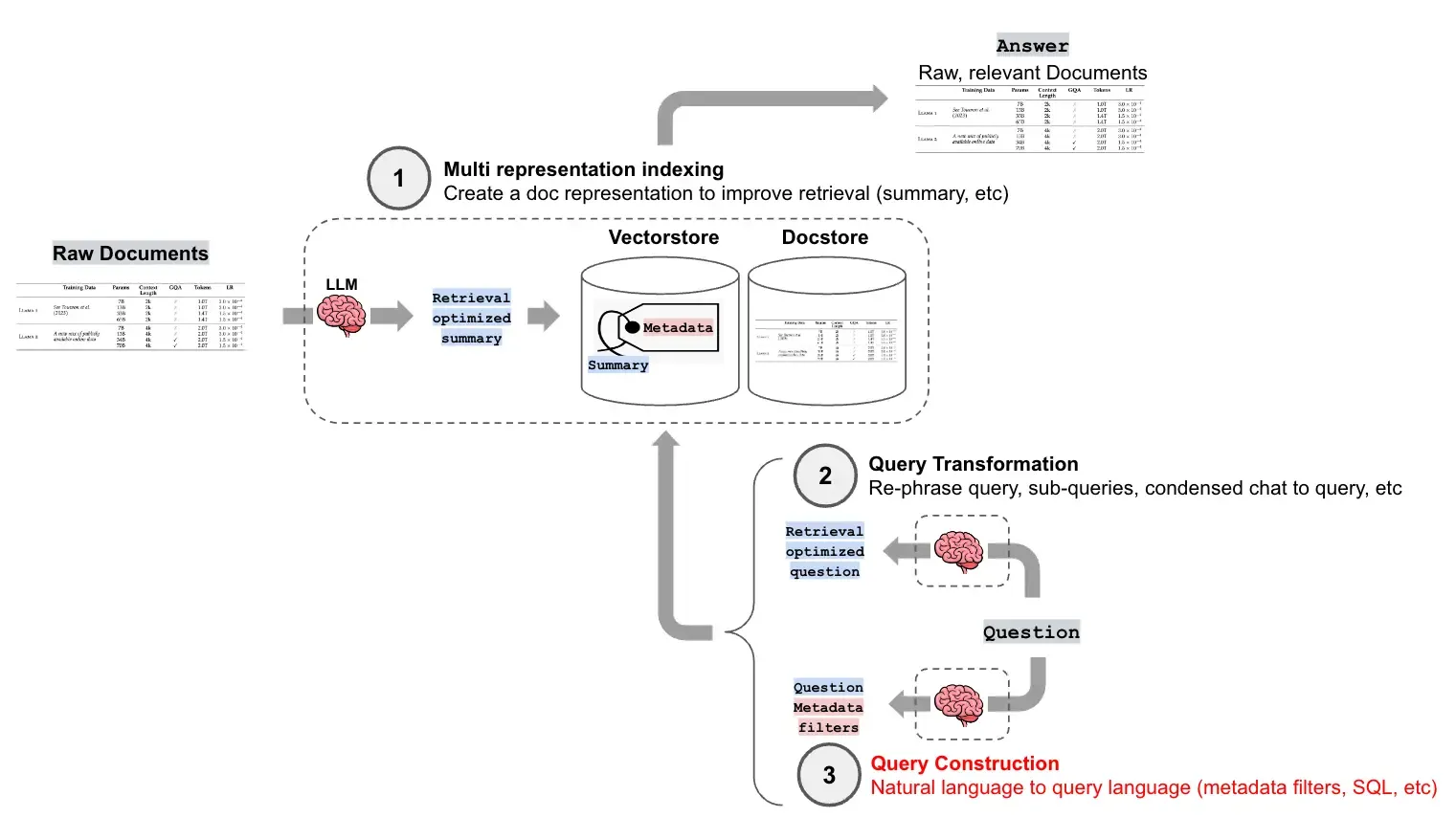
2. 从文本到元数据过滤器
在构建向量索引时,常常会为文档块(Chunks)附加元数据(Metadata),例如文档来源、发布日期、作者、章节、类别等。这些元数据为我们提供了在语义搜索之外进行精确过滤的可能。
自查询检索器(Self-Query Retriever) 是LangChain中实现这一功能的核心组件。它的工作流程如下:
- 定义元数据结构:首先,需要向LLM清晰地描述文档内容和每个元数据字段的含义及类型。
- 查询解析:当用户输入一个自然语言查询时,自查询检索器会调用LLM,将查询分解为两部分:
- 查询字符串(Query String):用于进行语义搜索的部分。
- 元数据过滤器(Metadata Filter):从查询中提取出的结构化过滤条件。
- 执行查询:检索器将解析出的查询字符串和元数据过滤器发送给向量数据库,执行一次同时包含语义搜索和元数据过滤的查询。
例如,对于查询"关于2022年发布的机器学习的论文",自查询检索器会将其解析为:
- 查询字符串: "机器学习的论文"
- 元数据过滤器: year == 2022
下面,来看看SelfQueryRetriever的最小示例:
Python3
点击展开代码
展开代码
提一嘴就是现在结构化主要通过Schema等验证去做了,你可以看到这个方法已经被放到langchain_classic.retrievers.self_query.base 里面了。
3. 从文本到Cypher
与"文本到元数据过滤器"类似,"文本到Cypher"技术利用大语言模型(LLM)将用户的自然语言问题直接翻译成一句精准的 Cypher 查询语句。LangChain 提供了相应的工具链(如 GraphCypherQAChain),其工作流程通常是:
- 接收用户的自然语言问题。
- LLM 根据预先提供的图谱模式(Schema),将问题转换为 Cypher 查询。
- 在图数据库上执行该查询,获取精确的结构化数据。
- (可选)将查询结果再次交由 LLM,生成通顺的自然语言答案。
由于生成有效的 Cypher 查询是一项复杂的任务,通常使用性能较强的 LLM 来确保转换的准确性。通过这种方式,用户可以用最自然的方式与高度结构化的图数据进行交互,极大地降低了数据查询的门槛。
4. Text2SQL
这是结构化数据领域中一个常见的应用。在数据世界中,除了向量数据库能够处理的非结构化数据,关系型数据库(如 MySQL, PostgreSQL, SQLite)同样是存储和管理结构化数据的重点。文本到SQL(Text-to-SQL)正是为了打破人与结构化数据之间的语言障碍而生。它利用大语言模型(LLM)将用户的自然语言问题,直接翻译成可以在数据库上执行的SQL查询语句。
专题阅读
RAG
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。