
把 RAG 评估拆成一条清晰的工作流:先看检索,再看生成,再看工具;这样系统效果出问题时,才知道到底是哪一段出了偏差。
这一篇不再讲"怎么搭",而是讲"怎么判断它到底有没有变好"。RAG 评估最重要的价值不只是打分,而是能把问题定位到检索层还是生成层。
RAG - 评估
我们需要量化地追踪、迭代并提升RAG应用的性能,当系统出现幻觉或答非所问的时候,快速定位问题。
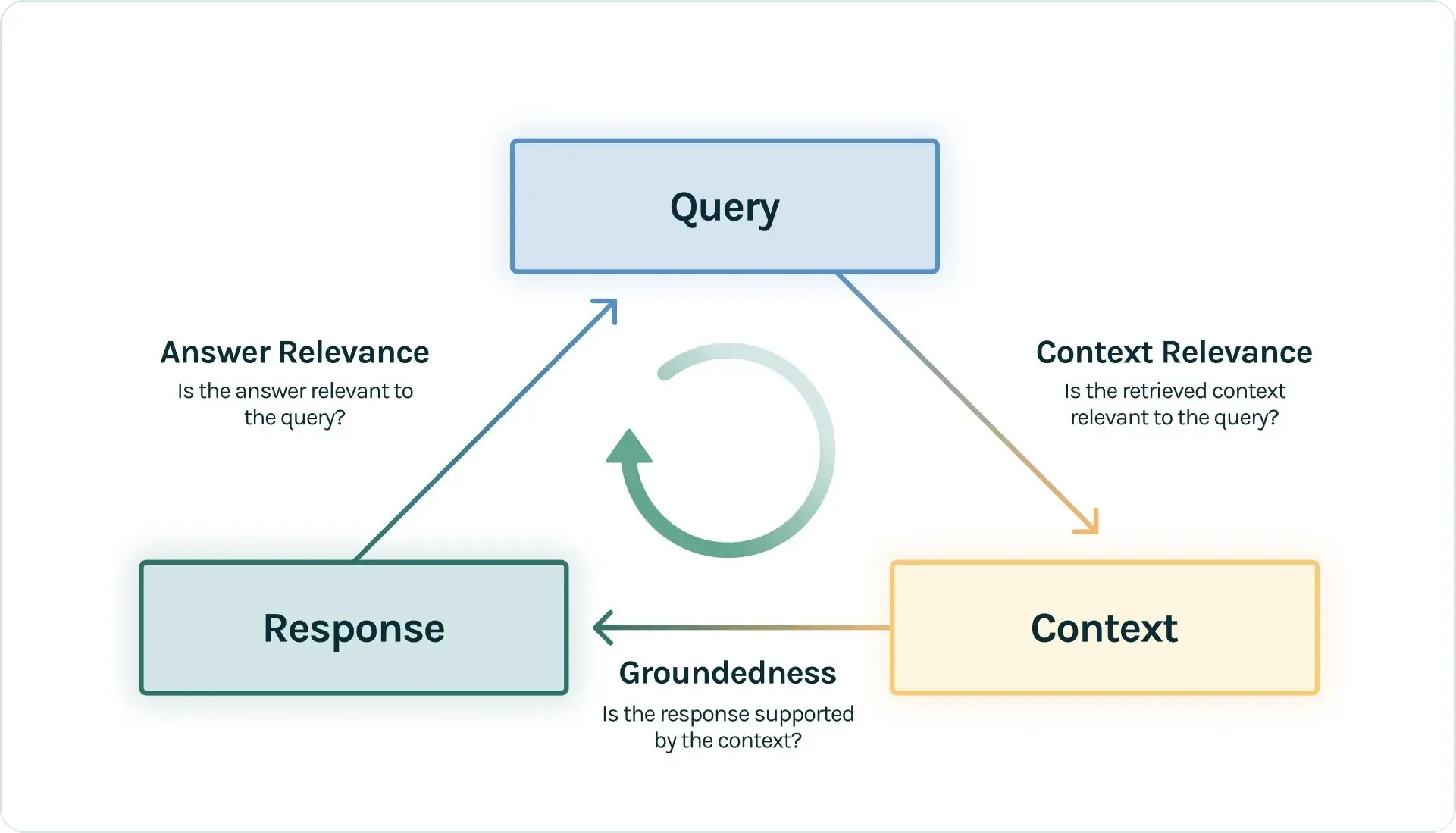
一、RAG评估三元组
- 上下文相关性 (Context Relevance)
- 评估目标: 检索器(Retriever)的性能。
- 核心问题: 检索到的上下文内容,是否与用户的查询(Query)高度相关?
- 重要性: 检索是RAG应用在响应用户查询时的第一步。如果检索回来的上下文充满了噪声或无关信息,那么无论后续的生成模型多么强大,都没法做出正确答案。
- 忠实度 / 可信度 (Faithfulness / Groundedness)
- 评估目标: 生成器的可靠性。
- 核心问题: 生成的答案是否完全基于所提供的上下文信息?
- 重要性: 这个维度主要在于量化LLM的"幻觉"程度。一个高忠实度的回答意味着模型严格遵守了上下文,没有捏造或歪曲事实。如果忠实度得分低,说明LLM在回答时"自由发挥"过度,引入了外部知识或不实信息。
- 答案相关性 (Answer Relevance)
- 评估目标: 系统的端到端(End-to-End)表现。
- 核心问题: 最终生成的答案是否直接、完整且有效地回答了用户的原始问题?
- 重要性: 这是用户最直观的感受。一个答案可能完全基于上下文(高忠实度),但如果它答非所问,或者只回答了问题的一部分,那么这个答案的相关性就很低。例如,当用户问"法国在哪里,首都是哪里?",如果答案只是"法国在西欧",那么虽然忠实度高,但答案相关性很低。
二、评估工作流
虽然前面把评估拆成了三个维度,但真正落地的时候,其实可以顺着一条更自然的工作流去理解:先评估检索,再评估响应。因为RAG本质上就是"先检索,再生成",前一环的问题会直接传递到后一环。
1. 检索评估
检索评估主要对应RAG三元组中的上下文相关性,更像是在做一次白盒测试。它不直接看最终回答,而是单独检查Retriever是否真的把相关文档找回来了。
这一阶段通常需要一个标注数据集,里面至少要有:
- 查询(Query)
- 每个查询对应的真实相关文档(Ground Truth)
有了这样的数据之后,就可以用传统信息检索里的指标来评估Retriever:
- Precision@k:看前k个结果里有多少是真的相关文档。它衡量的是"准不准"。
其中, 表示只看前 个检索结果。分子是这 个结果里真正相关的文档数,分母就是被拿来评估的结果总数 。
- Recall@k:看所有应该被找回的相关文档里,有多少真的被找回来了。它衡量的是"全不全"。
这里的分子和 Precision@k 一样,仍然是前 个结果中命中的相关文档数;但分母换成了数据集中这个查询对应的全部相关文档数,因此它衡量的是系统有没有把该找回来的内容尽量找全。
- F1:Precision和Recall的调和平均,相当于在"准确"和"完整"之间取平衡。
其中,Precision 表示准确率,Recall 表示召回率。这个式子本质上是在对两者做调和平均,因此只要其中一个值很低, 就会被明显拉低。
- MRR(平均倒数排名,Mean Reciprocal Rank):看第一个正确文档排得靠不靠前,适合用户通常只看第一个正确答案的场景。
其中, 是查询总数, 是第 个查询中第一个相关文档的排名。第一个相关文档排得越靠前,倒数值就越大,因此整体 MRR 也越高。
- MAP(平均准确率均值,Mean Average Precision):综合考虑多个相关文档的排序质量,比单纯看第一个正确结果更全面。
其中, 是查询总数, 是第 个查询的平均准确率。也就是说,MAP 先分别计算每个查询自己的排序质量,再对所有查询取平均。
所以这一阶段的重点不是让模型回答得像不像人,而是先回答一个更基础的问题:知识到底有没有被正确召回。如果检索本身就错了,后面的生成质量通常也不会高。
2. 响应评估
响应评估主要对应RAG三元组中的忠实度和答案相关性,它更像端到端测试。这里不再只看Retriever,而是直接看用户最终拿到的答案质量。
这部分通常围绕两个问题展开:
- 忠实度:答案是不是严格基于检索到的上下文,有没有幻觉。
- 答案相关性:答案有没有真正回答用户的问题,是否切题、完整。
常见的评估方法主要有两类。
第一类是基于LLM的评估。做法是再找一个高性能模型充当评委,让它来判断答案是否忠实、是否切题。
- 在忠实度评估里,通常会先把答案拆成若干条陈述,再逐条检查这些陈述能不能从上下文中得到支持。
- 在答案相关性评估里,评委模型会同时看问题和答案,判断答案是否答非所问,或者虽然没幻觉但只回答了一半。
第二类是基于词汇重叠的经典指标,前提是数据集中有标准答案。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)更关注召回率,偏向评估内容有没有覆盖完整。
其中, 表示连续词组的长度,例如 时是 unigram, 时是 bigram。分子表示生成答案和参考答案之间匹配到的 -gram 数量,分母表示参考答案里总共有多少个 -gram,因此它本质上更偏召回率。
- BLEU(Bilingual Evaluation Understudy)更关注精确率,同时会用长度惩罚避免答案过短。
其中, 是长度惩罚项(Brevity Penalty),用于防止模型只靠生成很短的句子拿高分; 是第 阶 -gram 的精确率, 是不同阶数精确率的权重, 表示最高统计到几阶 -gram。
- METEOR(Metric for Evaluation of Translation with Explicit ORdering)会同时考虑精确率、召回率,以及一定程度上的同义词和词干匹配,通常比BLEU更贴近人类判断。
这里的 表示精确率, 表示召回率, 用来控制两者的相对权重。这个 可以看成是 Precision 和 Recall 的加权调和平均。
其中, 是惩罚项,主要用于惩罚词序混乱或匹配片段过于零散的情况。因此 METEOR 不仅看匹配到了多少内容,也会考虑这些内容的组织是否自然。
这两类方法各有特点:
- 基于LLM的评估更懂语义,适合判断忠实度和答案是否真的切题,但成本更高,也可能带有评判模型本身的偏见。
- 经典指标更快、更便宜,也更客观,但它们很难真正理解语义,只能看表面词汇是否重合。
因此,一个比较自然的评估工作流可以总结为:
- 先用检索评估确认上下文有没有找对。
- 再用响应评估判断答案有没有基于这些上下文正确生成。
- 如果想大规模快速评测,可以先用ROUGE、BLEU这类便宜指标筛一遍;如果想看更真实的回答质量,再引入LLM-as-a-Judge做精细评估。
这样做的好处是,当系统效果不好时,我们可以更容易定位问题到底出在:
- 检索没找准
- 还是生成阶段出现了幻觉、答非所问
三、评估工具
- LlamaIndex Evaluation:LlamaIndex Evaluation 是深度集成于LlamaIndex框架内的评估模块,专为使用该框架构建的RAG应用提供无缝的评估能力。
- RAGAS(RAG Assessment):是一个独立的、专注于RAG的开源评估框架。提供了一套全面的指标来量化RAG管道的检索和生成两大核心环节的性能。其最显著的特色是支持无参考评估,即在许多场景下无需人工标注的"标准答案"即可进行评估,极大地降低了评估成本。
- Phoenix(Arize Phoenix):是一个开源的LLM可观测性与评估平台。在RAG评估生态中,它主要扮演生产环境中的可视化分析与故障诊断引擎的角色。
| 工具 | 核心机制 | 独特技术 | 典型应用场景 |
|---|---|---|---|
| RAGAS | LLM 驱动评估 | 合成数据生成、无参考评估架构 | 对比不同 RAG 策略、版本迭代后的性能回归测试 |
| LlamaIndex | 嵌入式评估 | 异步评估引擎、模块化 BaseEvaluator | 开发过程中快速验证单个组件或完整管道的效果 |
| Phoenix | 追踪分析型 | 分布式追踪、向量聚类分析算法 | 生产环境监控、Bad Case 分析、数据漂移检测 |
专题阅读
RAG
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。