
从最基础的问题开始:什么场景下需要微调,微调的一般流程是什么,以及全参数微调、冻结微调、PEFT 分别在解决什么问题。
这一篇先不急着进工具和参数,而是先把"为什么要微调"这件事想清楚。只有先搞清楚目标,后面看 LoRA、数据集和训练参数时才不会只剩操作步骤。
一、为什么要微调
有时候,即使采用本地部署加知识库,也不能很好满足某些场景。因为常见大模型虽然基于海量数据训练,具备广泛的通用能力,但在特定领域、特定任务和特定输出风格上,往往还不够稳定。
通常会希望模型额外具备下面几类能力:
- 领域专业化:行业黑话、专业术语、专门知识要更稳地理解。
- 任务适配:希望输出风格、格式和结构更固定。
- 能力纠偏:在冷门场景或长尾问题上减少跑偏。
从问题拆解的角度看,长文本、知识库和微调并不是互斥关系,而是三种不同的优化方向。
| 对比维度 | 长文本处理 | 知识库 | 微调 |
|---|---|---|---|
| 核心目标 | 理解和生成长篇内容 | 提供背景知识,增强回答能力 | 优化模型在特定任务或领域的表现 |
| 优点 | 连贯性强,适合复杂任务 | 灵活性高,可随时更新 | 性能提升,定制化强 |
| 缺点 | 资源消耗大,上下文限制明显 | 依赖检索,实时性要求高 | 需要标注数据,训练成本高 |
| 适用场景 | 写作助手、长文理解 | 智能客服、问答系统 | 专业领域、固定任务、风格定制 |
| 实时性 | 静态,依赖输入 | 动态,知识库可更新 | 静态,训练后固定 |
所以微调更像是在回答一个问题:
当模型不仅要"知道",还要"稳定地按某种方式做"时,是不是该把这种能力真正写进参数里。
二、一个微调的大致流程
微调的一般过程可以概括为 7 步:
- 选定预训练模型。
- 准备并加载微调数据集。
- 先准备一组固定问题,用于微调前后对比。
- 设定训练超参数。
- 进行训练。
- 评估训练后的回答效果。
- 不满意就继续调数据、调参数、重新训练。
这条流程看起来很简单,但真正最耗时间的其实是中间三件事:
- 数据集怎么组织
- 参数怎么选
- 结果怎么解释
后面几篇会分别把这三块拆开。
三、微调可以怎么分类
微调可以从很多维度分类。这里先保留原笔记里的三条主线:学习范式、参数更新范围、任务类型。
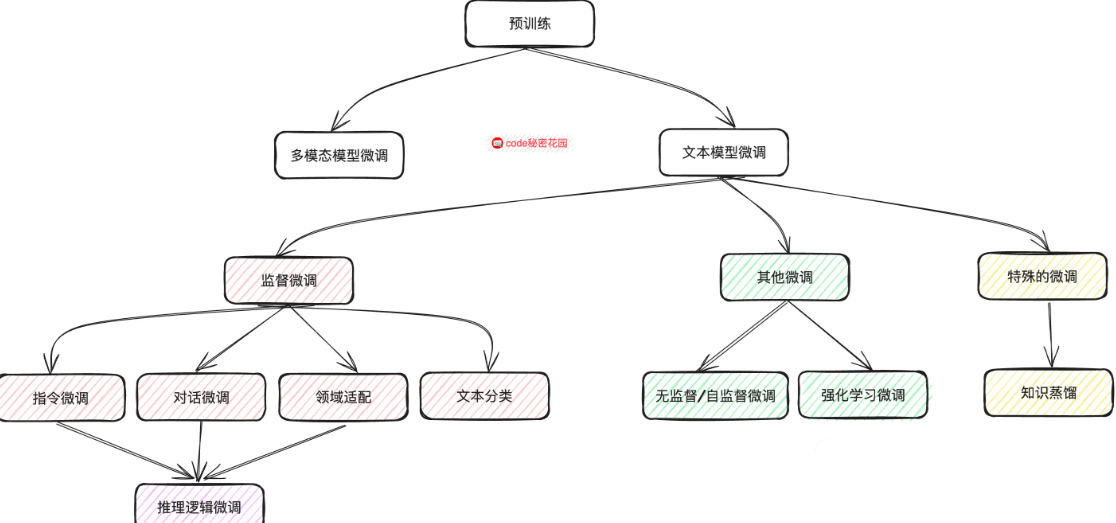
1. 按学习范式
(1)预训练
通常不是微调者自己做的阶段,而是通用大模型已经完成的那一轮大规模学习。预训练模型先学到通用语言规律、图像规律或多模态对齐能力,微调是在这个基础上继续塑形。
(2)监督微调(SFT)
监督微调是最常见、也最容易上手的一类微调。它使用带标签的任务数据继续训练模型,让模型更会做某个特定任务。
比如做英译中,只要数据集中提供英文输入和中文输出,模型就会被拉向这个映射关系。
(3)无监督微调
无监督微调使用没有标签但与任务相关的数据继续训练模型。它依赖的是数据本身的分布规律,而不是人工标注。
常见的无监督学习目标有两类:
- 自回归:根据前面的 token 预测下一个 token,代表模型是 GPT、LLaMA、Claude 等。
- 自编码:根据上下文预测被 mask 的 token,代表模型是 BERT、RoBERTa、BART 等。
(4)自监督微调
自监督其实是无监督学习里最重要的一支。它不是单纯"没有标签",而是通过数据本身构造监督信号,相当于让模型自己给自己出题。
GPT 的自回归、BERT 的掩码预测都属于自监督范式。
(5)强化学习微调
这一类和前面差别很大,它不再只是"对着标准答案学",而是通过奖励信号优化输出,让结果更符合人类偏好。
| 特性 | 监督微调 | 无监督 / 自监督微调 | 强化学习微调 |
|---|---|---|---|
| 核心数据 | 带标签任务数据 | 无标签任务数据 | 人类偏好 / 奖励信号 |
| 主要目标 | 特定任务性能 | 领域适应 | 对齐人类偏好 |
| 典型技术 | 交叉熵损失 | 自回归、掩码学习、对比学习 | PPO、DPO 等 |
| 数据成本 | 高 | 低 | 很高 |
| 流程复杂度 | 低 | 中 | 很高 |
如果目标是明确分类任务,多数情况下 SFT 就足够了。
2. 按参数更新范围
这是微调里最现实的一组分类,因为它直接决定硬件要求和训练成本。
(1)全参数微调
最直接的方法:加载全部权重,在下游数据上更新所有参数。
优点是理论潜力最大;缺点是显存、算力和过拟合风险都最高。
(2)冻结微调
冻结大部分预训练层,只替换或解冻最后几层做训练。思路是:底层特征往往更通用,顶层特征更贴近任务。
(3)参数高效微调(PEFT)
PEFT 的目标很明确:只训练极少量参数,但尽可能保留接近全参数微调的效果。
它大体又可以分成几类:
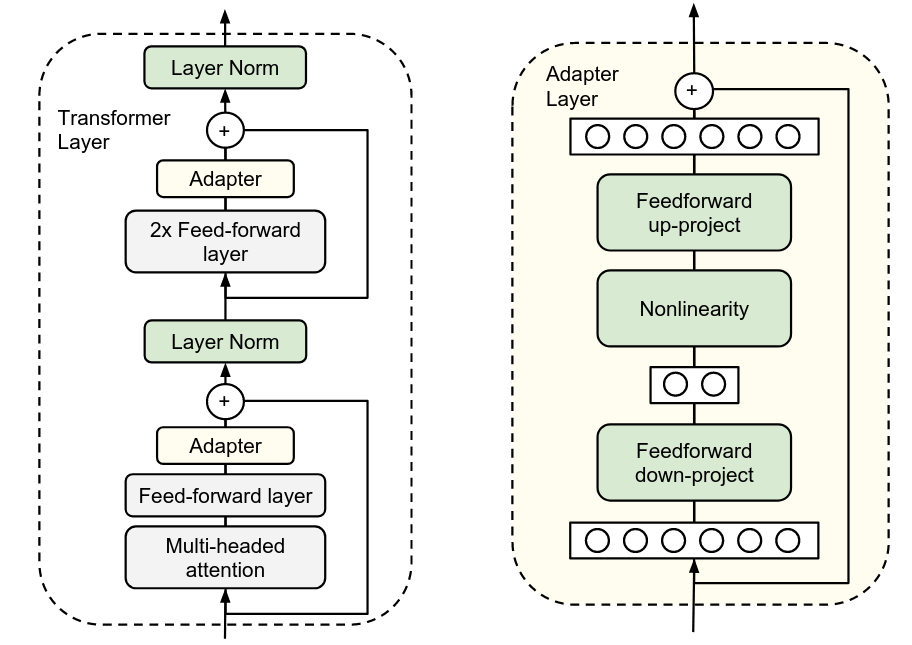
① 适配器类
在原模型结构里插入一些小模块,训练这些新模块,冻结原始参数。
- Adapter Tuning
- Parallel Adapter
- LoRA
| 特性 | Adapter Tuning | Parallel Adapter | LoRA |
|---|---|---|---|
| 核心思想 | 串行插入 Adapter 模块 | 与原模块并行放置 Adapter | 用低秩矩阵近似权重更新 |
| 推理速度 | 会引入串行延迟 | 延迟较低 | 几乎无推理延迟 |
| 主要优点 | 参数效率高 | 结构更高效 | 参数少、部署方便、最主流 |
| 主要缺点 | 推理变慢 | 效果依赖实现 | 低秩假设并非总能完全覆盖复杂变化 |
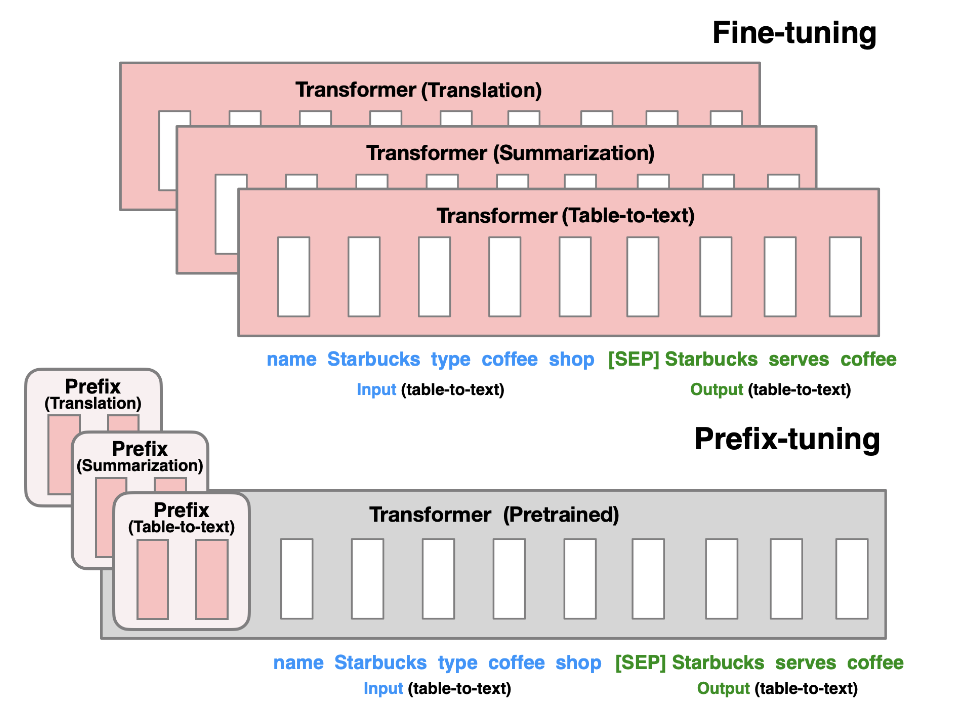
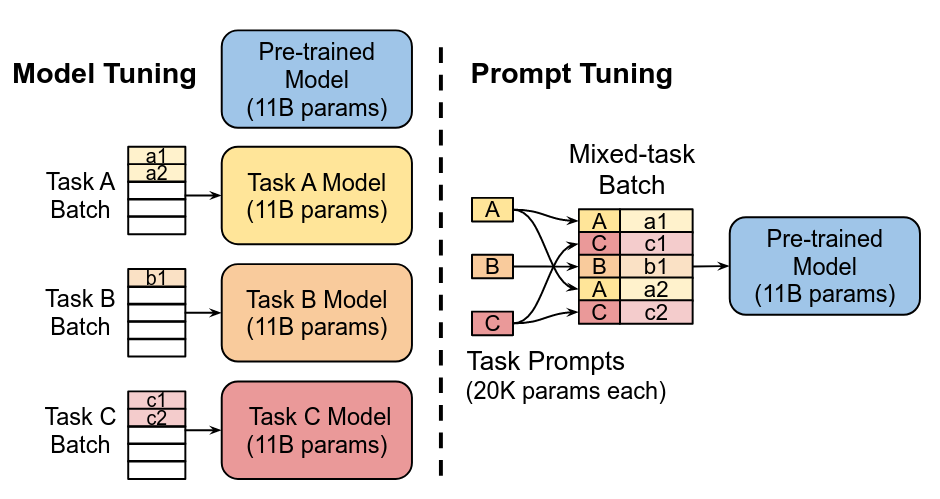
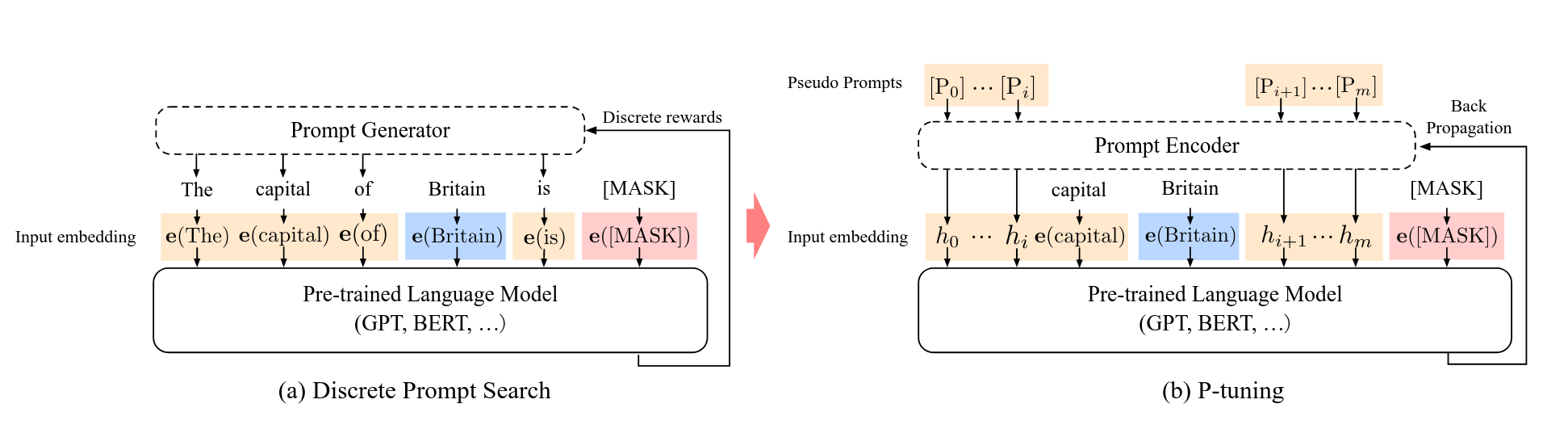
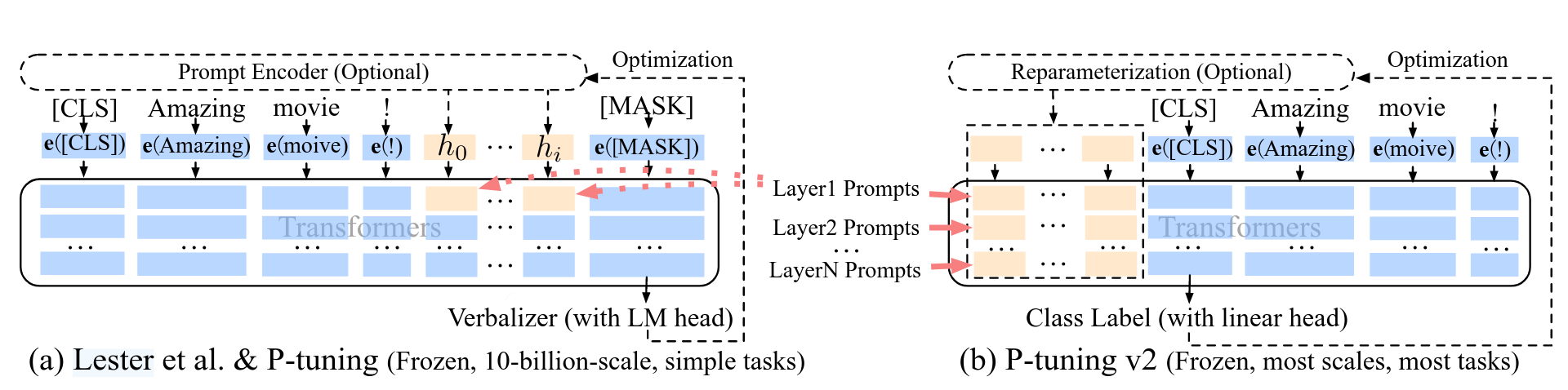
② 提示工程类
通过加入可训练的软提示,让冻结模型朝任务方向偏移。
- Prefix Tuning
- Prompt Tuning
- P-Tuning
- P-Tuning v2
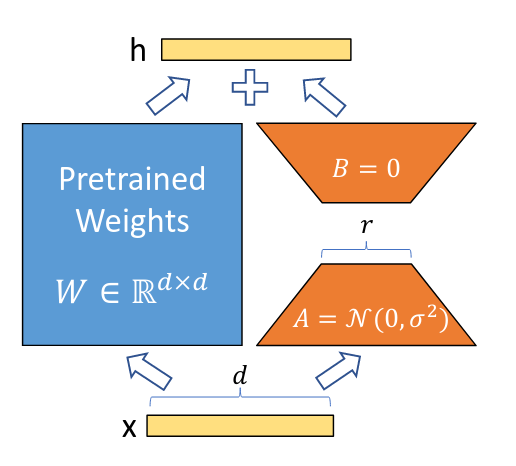
③ 低秩适配类
核心思想是利用低秩矩阵模拟权重更新。
- LoRA
- QLoRA
- Delta-LoRA
④ 稀疏方法类
核心思想是只训练原模型参数中的一个稀疏子集。
- BitFit
- Fish Mask
- Intrinsic SAID
3. 按任务类型
这条线更贴近业务目标:
- 指令微调
- 领域适应微调
- 风格迁移微调
- 多模态微调
如果目标是"让 Qwen2.5-VL 更懂某类图像并完成固定分类任务",那它显然属于:
- 多模态微调
- 监督微调
- 参数高效微调里的 LoRA / QLoRA 路线
四、先留下一个实践判断
这组笔记最后要做的是多模态图像分类任务,所以最终选择监督微调,并优先考虑 LoRA 这类参数高效方法。这不是因为它"理论最高级",而是因为它在硬件条件、数据规模和任务目标之间最平衡。
专题阅读
Fine Tuning
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。