
把原笔记里和量化相关的部分单独抽出来:先讲目的,再讲原理、分类和常用方法,最后把它和 QLoRA 重新连回到微调主线里。
量化和微调经常一起出现,尤其一说到 QLoRA 就会默认它们属于一套东西。但更顺的理解方式其实是先把量化单独拆开:它先是模型压缩与推理优化技术,然后才在 QLoRA 里与微调发生结合。
一、为什么要量化
模型量化的核心,是把高精度数据(通常是 FP32)转换成更低精度的数据表示。
它最直接的目标有三个:
- 减少模型大小
- 降低显存或内存占用
- 提升推理速度
代价也很明确:精度可能损失。
所以量化从来都不是"白送的加速",而是一种典型的精度与资源交换。
二、量化的原理
量化本质上是在做一件事:
把连续浮点区间,映射到有限的离散整数区间。
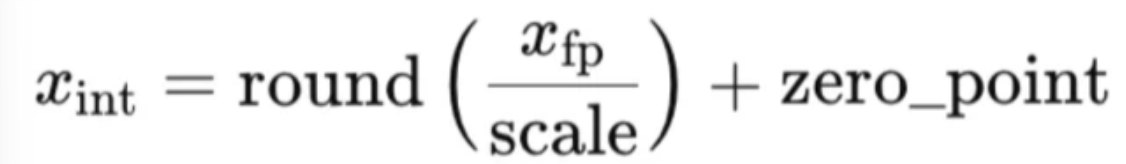
原笔记里的几个核心量是:
x_fp:原始浮点值x_int:量化后的整数值scale:缩放因子zero_point:零点偏移
可以把它粗理解为"比例缩放 + 偏移对齐"。
三、量化可以怎么分类
1. 按量化时机
(1)训练后量化(PTQ)
先正常训练,再在模型训练完之后直接量化。
优点是快、实现简单;缺点是精度损失可能比较明显,尤其在小模型上。
QLoRA 里常见的 4-bit NF4 量化,本质上也是"微调前先把基础模型量化"。
(2)量化感知训练(QAT)
在训练时就模拟量化和反量化过程,让模型提前适应低精度带来的误差。
这类方法通常更稳,但实现复杂度和训练成本更高。
2. 按量化精度
| 类型 | 权重精度 | 激活值精度 | 特点 | 代表技术 |
|---|---|---|---|---|
| FP16 / BF16 | 16-bit | 16-bit | 更偏训练加速与存储节省,通常可视为近乎无损 | AMP |
| INT8 | 8-bit | 8-bit | 最主流的推理精度,精度和效率平衡较好 | TensorRT, ONNX Runtime |
| INT4 / NF4 | 4-bit | 8-bit / 4-bit | 极致压缩,适合消费级硬件跑大模型 | QLoRA, GPTQ, AWQ |
| 1-bit / 2-bit | 1/2-bit | 32-bit / 1-bit | 学术前沿,压缩极致,但落地难 | BinaryConnect |
3. 按量化对象
(1)仅权重量化
只量化模型权重,激活值仍然保留较高精度。
(2)权重与激活值全量化
推理过程中权重和激活值都被量化到低精度,进一步压缩,但实现难度更高。
4. 按量化策略
| 类型 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 对称量化 | 把 [-α, α] 映射到对称整数区间,zero_point = 0 | 计算简单 | 不适合明显偏斜的数据分布 |
| 非对称量化 | 把 [β, α] 映射到非对称整数区间,zero_point ≠ 0 | 更充分利用整数区间,误差更小 | 计算稍复杂 |
四、常见量化方法
1. bitsandbytes(bnb)
这是 QLoRA 最经典也最常见的配套库,支持 8-bit 与 4-bit,尤其 4-bit NF4 是它的代表能力之一。
优点是:
- 社区最成熟
- Hugging Face 生态集成最好
- 对 LoRA / QLoRA 训练非常友好
2. HQQ
HQQ 的特点是尽量减少对校准数据的依赖。相比传统量化要先拿一批校准样本统计分布,HQQ 更强调快速量化和更灵活的冷启动。
3. EETQ
EETQ 是 NVIDIA 推出的 8-bit 推理方案,更偏高吞吐的工程落地路线,和 TensorRT 这类 NVIDIA 生态结合得更深。
五、量化和微调是怎么接起来的
到这里,量化还只是"压缩模型"的技术。但一旦和 LoRA 结合起来,它就从纯推理优化,变成了一条真正改变训练门槛的路线。
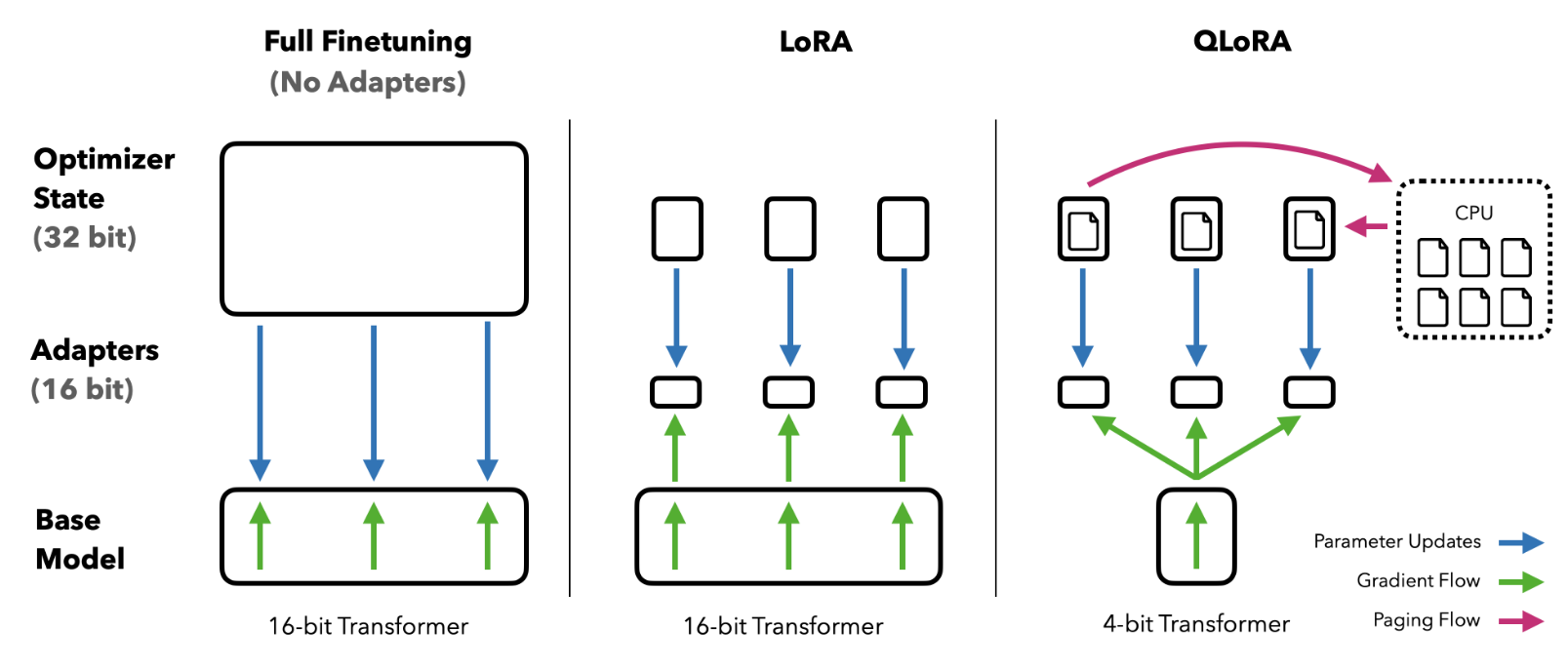
QLoRA 的关键思路是:
- 先把基础模型量化到 4-bit
- 冻结这些量化权重
- 只训练 LoRA 增量参数
这样做的好处不是"量化本身更聪明",而是:
把原本需要很大显存才能做的微调,压到了普通单机甚至消费级设备也能尝试的区间。
所以量化在这里的价值,不只是推理更省资源,而是直接改变了"谁有能力做微调"的门槛。
专题阅读
Fine Tuning
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。