
把第一次真正落地的多模态微调实验完整记下来:任务是什么,数据怎么标,参数怎么设,训练结果怎么看,以及为什么它只算“有进展但还远不够好”。
前面的几篇都还是"搭心智模型"。这一篇开始真正进入实践:用极少样本先把完整训练流程跑通,再看它到底学到了什么、没学到什么。
一、任务和现实约束
这次实验的目标,是让 Qwen2.5-VL 对血液图片做描述和分类。任务并不只是"看出这是一张血迹图",而是要进一步判断它属于哪一类血液形态。
原笔记里给出的核心背景是:
- 数据涉密,不能上传到公开在线服务
- 通用多模态模型能看出"这是红色液体",但不理解"血液形态"这一任务本身
- 样本非常少,只能先做一次小样本试跑
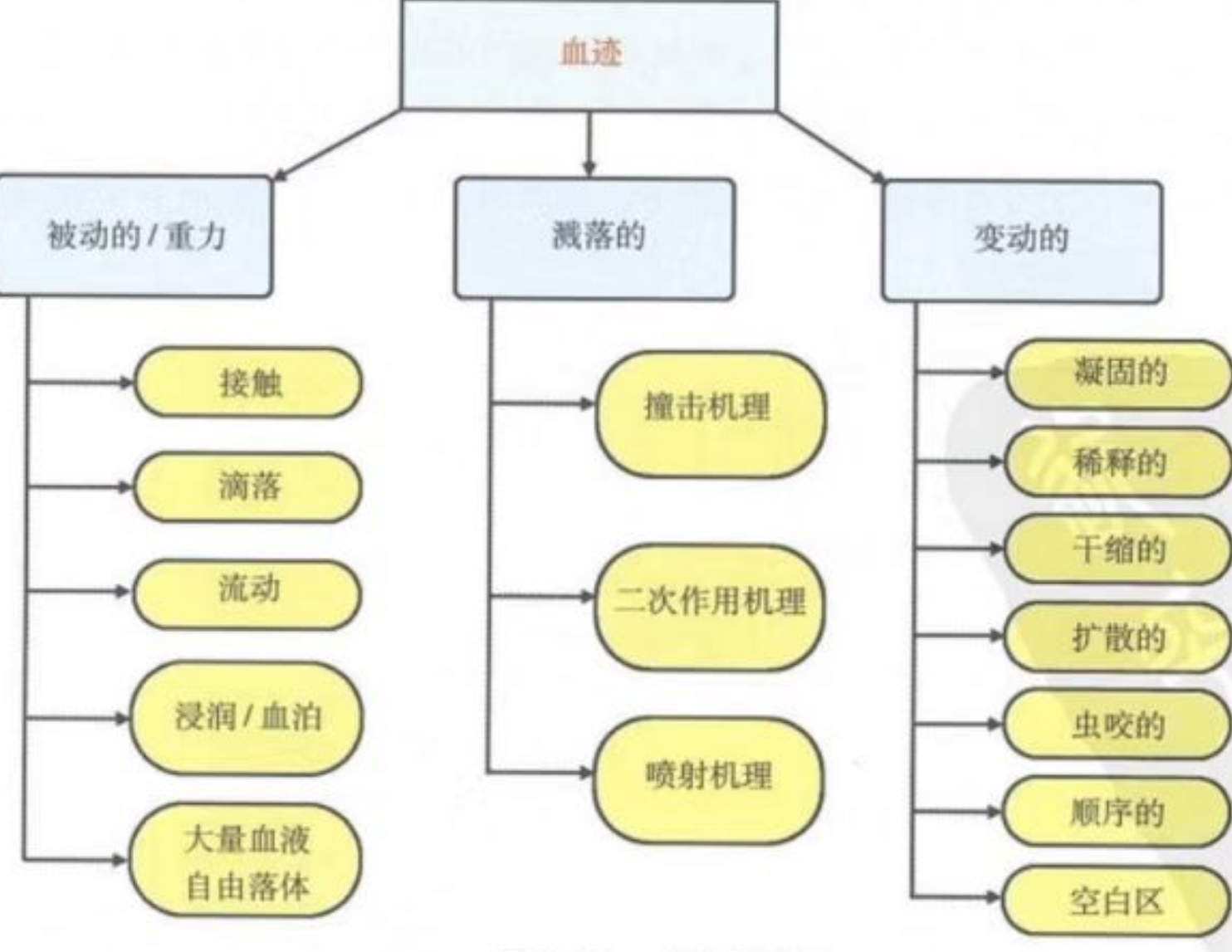
所以这次训练的目的,不是一步到位得到高精度模型,而是:
先把完整流程跑通,并尽快暴露问题。
二、数据怎么标出来
为了提高标注效率,原笔记里先用 clip-vit-large-patch14 做了一层预处理,然后配了一个交互式 Flask 标注工具,用来不断补全 conversations 字段。
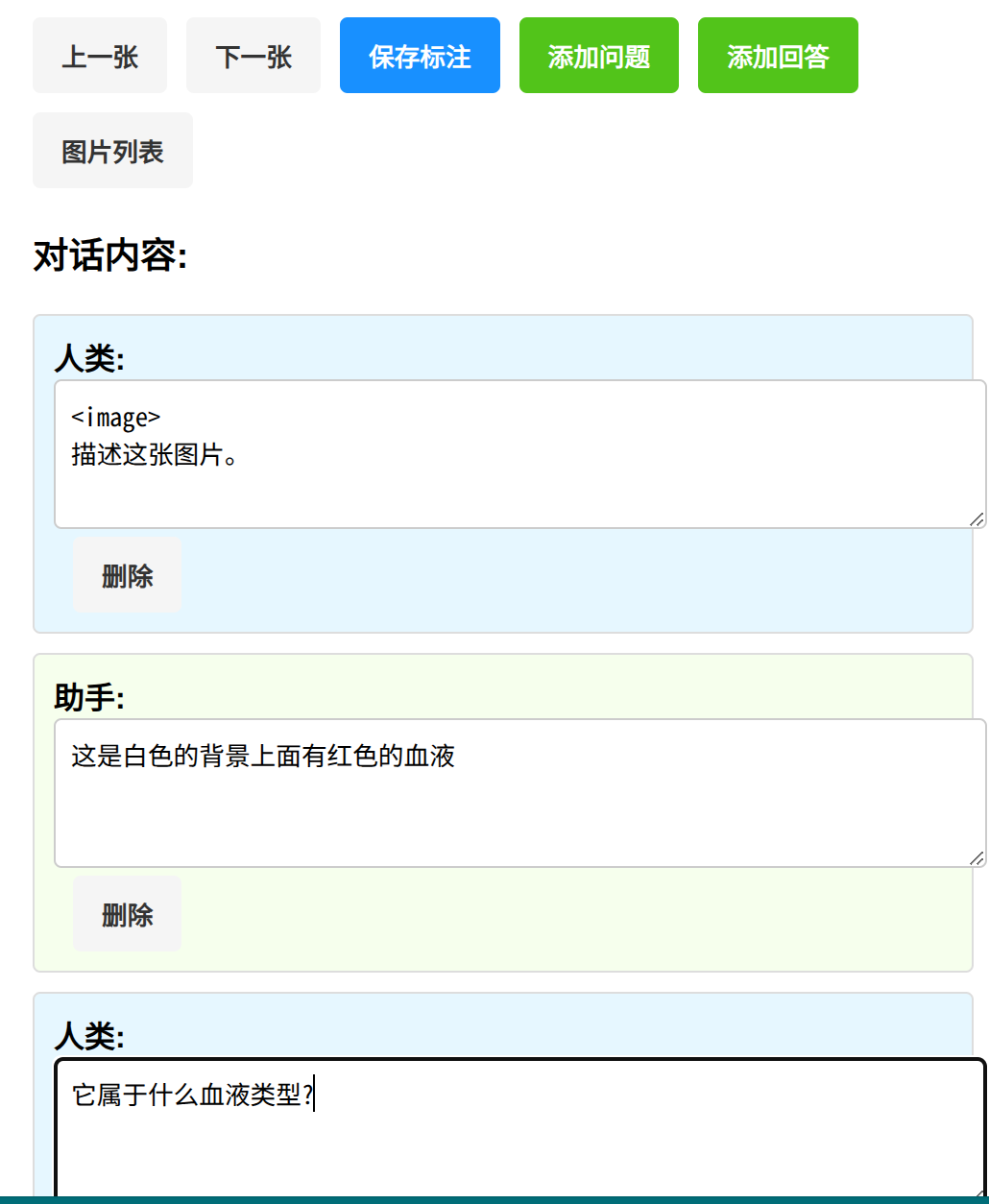
最终生成的就是多模态 ShareGPT 风格数据集:
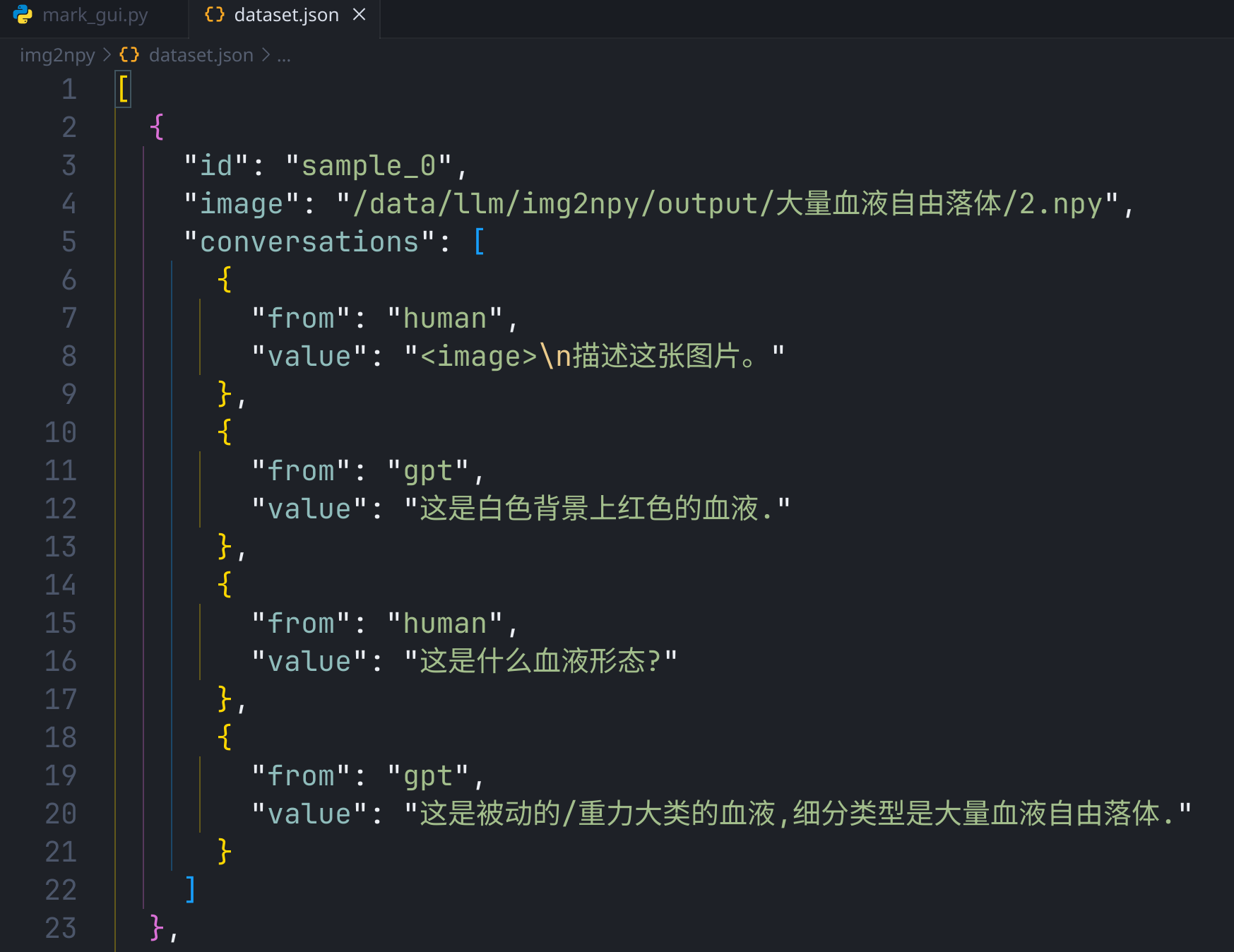
在这次试验里:
- 总样本量非常少
- 五个小类各自保留 2 个作为测试
- 其余样本进入训练
这本身就决定了结果不会太稳定,但也正因为如此,它特别适合用来观察流程问题。
三、第一次训练时怎么选参数
训练前先统计了 token 长度,确认大部分数据都在 1000 以内,所以 cutoff_len=2048 足够。

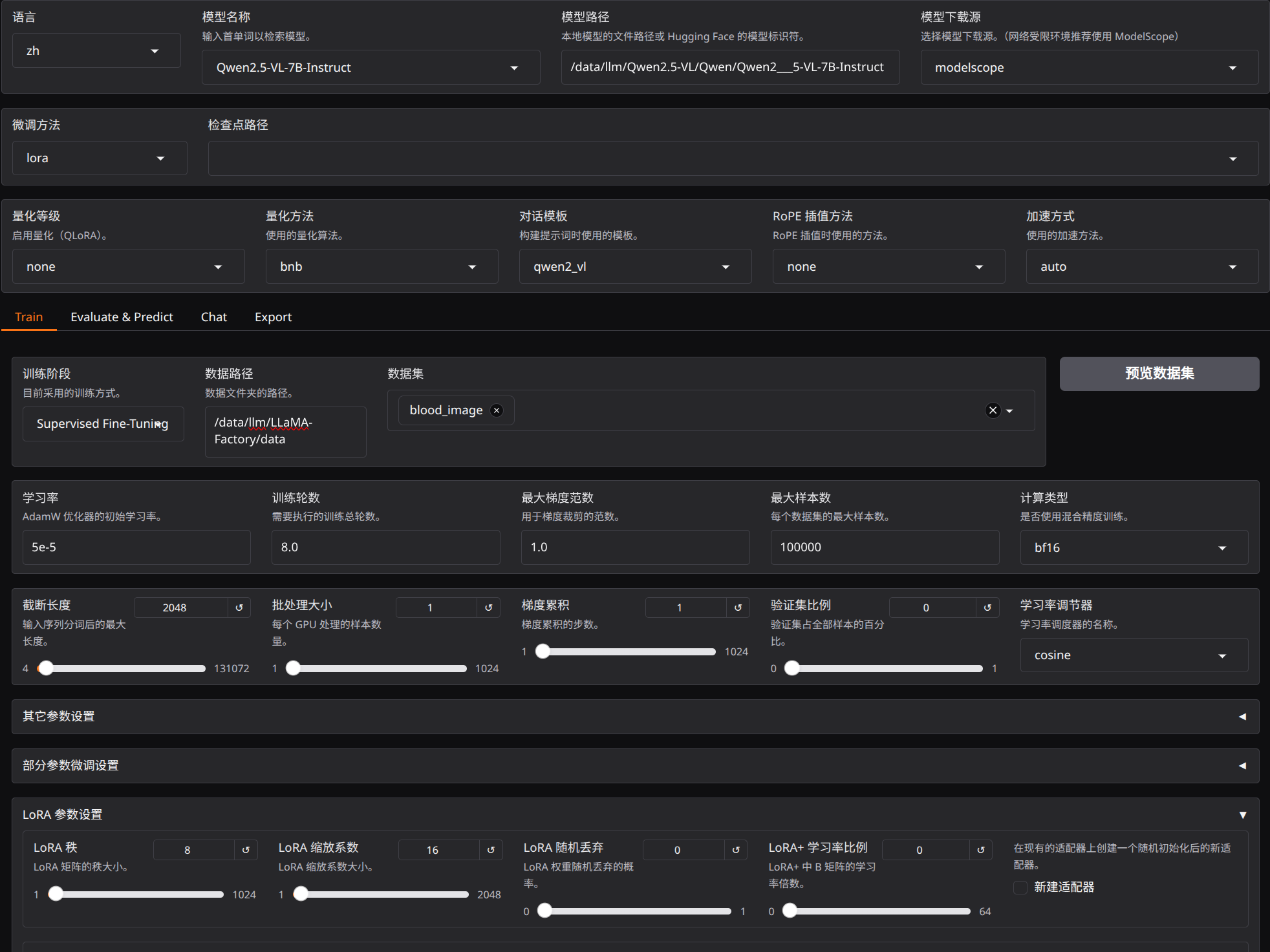
再结合前面那篇参数选择的经验,第一次训练采用了下面这组设置:
num_train_epochs=8per_device_train_batch_size=1gradient_accumulation_steps=1learning_rate=5e-5lora_rank=8lora_alpha=16validation split = 0
参数面板如下:
训练命令的核心部分如下:
llamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path /data/llm/Qwen2.5-VL/Qwen/Qwen2___5-VL-7B-Instruct \ --finetuning_type lora \ --template qwen2_vl \ --dataset blood_image \ --cutoff_len 2048 \ --learning_rate 5e-05 \ --num_train_epochs 8.0 \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 1 \ --optim adamw_torch \ --lora_rank 8 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_target all \ --freeze_vision_tower True \ --freeze_multi_modal_projector True原笔记里对这组选择的直觉其实很清楚:
- 样本少,所以 batch 先取小,尽量让模型多"看细节"
- LoRA 还是先从保守配置开始
- 验证集先不开,先看训练能不能跑通、Loss 是否合理
四、第一次训练出来了什么
训练过程如下:
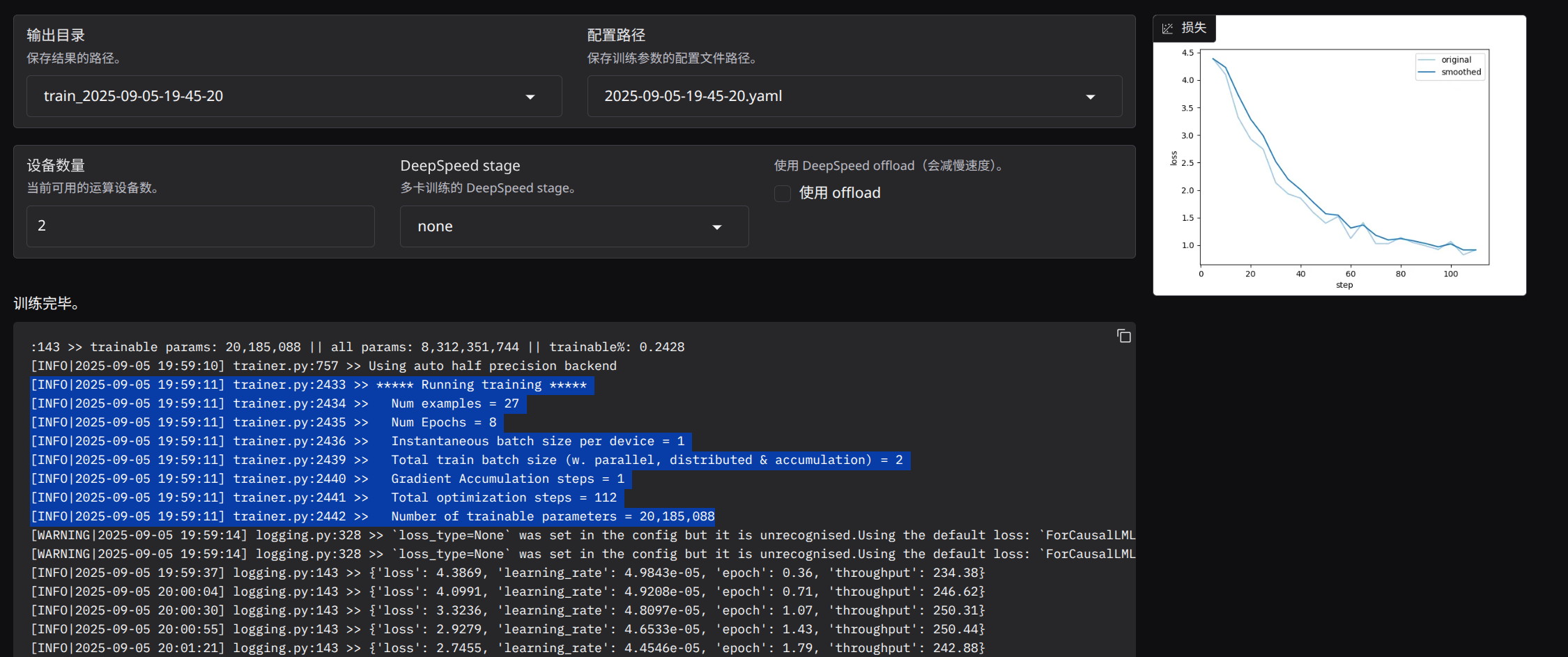
其中一个非常有意思的点,是 Total optimization steps = 112 并不是手工直接设的,而是由参数推出来的:
- 双卡训练
- 每卡 batch size = 1
- 总 batch = 2
- 梯度累积 = 1
- 27 个训练样本,
ceil(27 / 2) = 14 - 训练 8 轮,
14 × 8 = 112
这个计算过程其实很适合刚接触训练流程时建立感知:
很多日志里的数字,不是神秘参数,而是别的参数共同决定出来的。
五、显存占用怎么估
原笔记里还做了一个很实用的粗估:
- 基础模型权重:Qwen2.5-VL-7B,BF16 大约 14GB
- 框架开销:约 1GB
- LoRA 适配器:约 0.5GB
- 激活值:约 2.5GB
合起来单卡大概在 18GB 左右。

这个估算和实际结果已经相当接近,说明对训练资源的判断是比较可靠的。
六、Loss 曲线怎么看
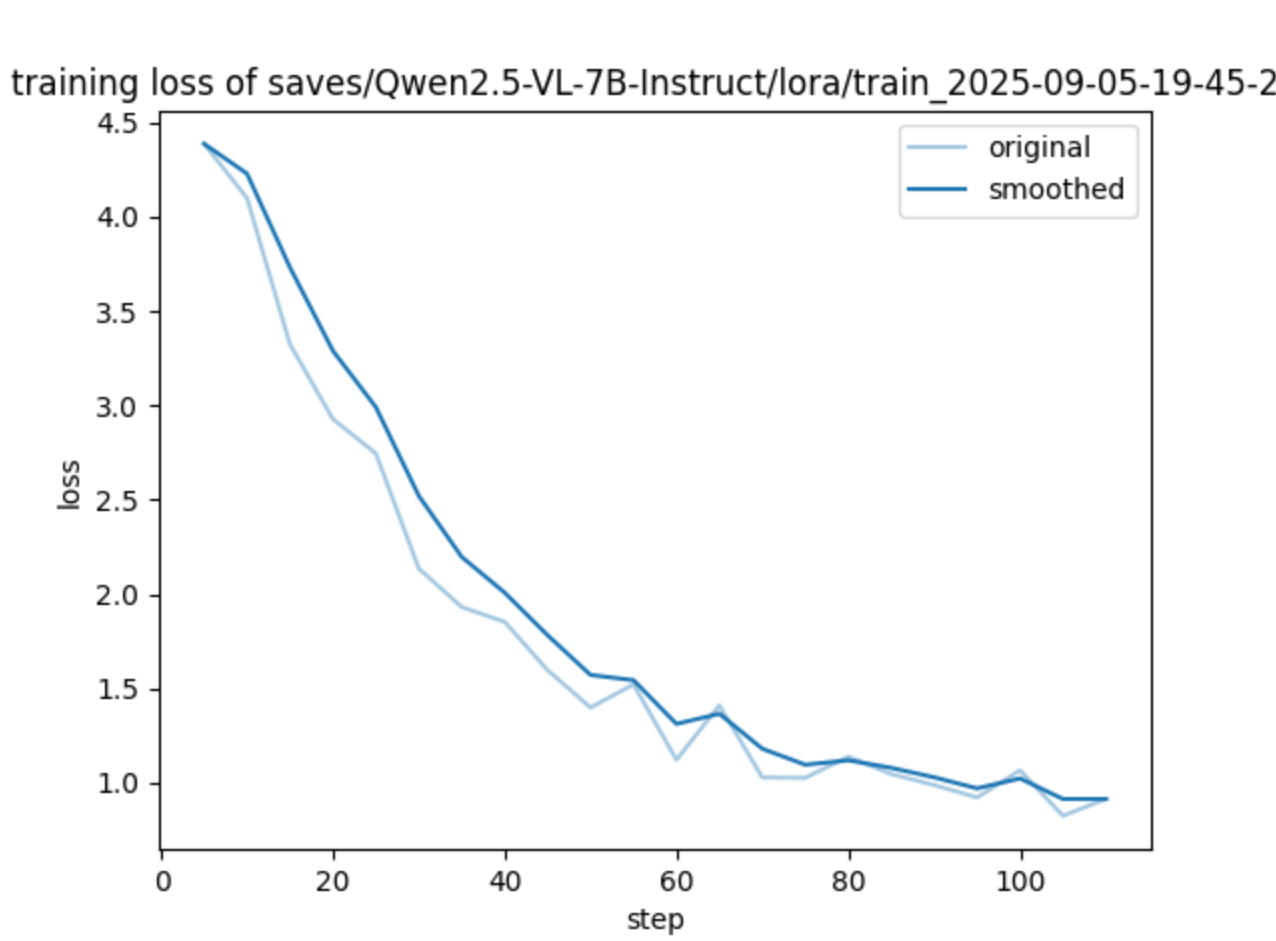
这条曲线整体是符合预期的:
- 有下降
- 在逐渐变缓
- 没出现明显发散
所以至少可以说明:
训练过程本身没有明显跑崩。
原笔记还顺手总结了几类常见坏曲线:
- Loss 居高不下:可能学习率太小,或者数据噪声太大
- 收敛很慢:可能轮数不够
- 上下震荡:可能学习率过大或 batch 太小
- 很早就卡住:可能学习率衰减过低、局部最优或过拟合
- 下降后又回升:通常要怀疑数据问题
这部分很重要,因为它提醒了一件事:
曲线正常,不等于任务完成得好。
七、训练后模型表现怎样
训练后的关键输出是 LoRA adapter 文件。加载方式本质上就是:
- 保留原始基础模型
- 叠加训练得到的 adapter
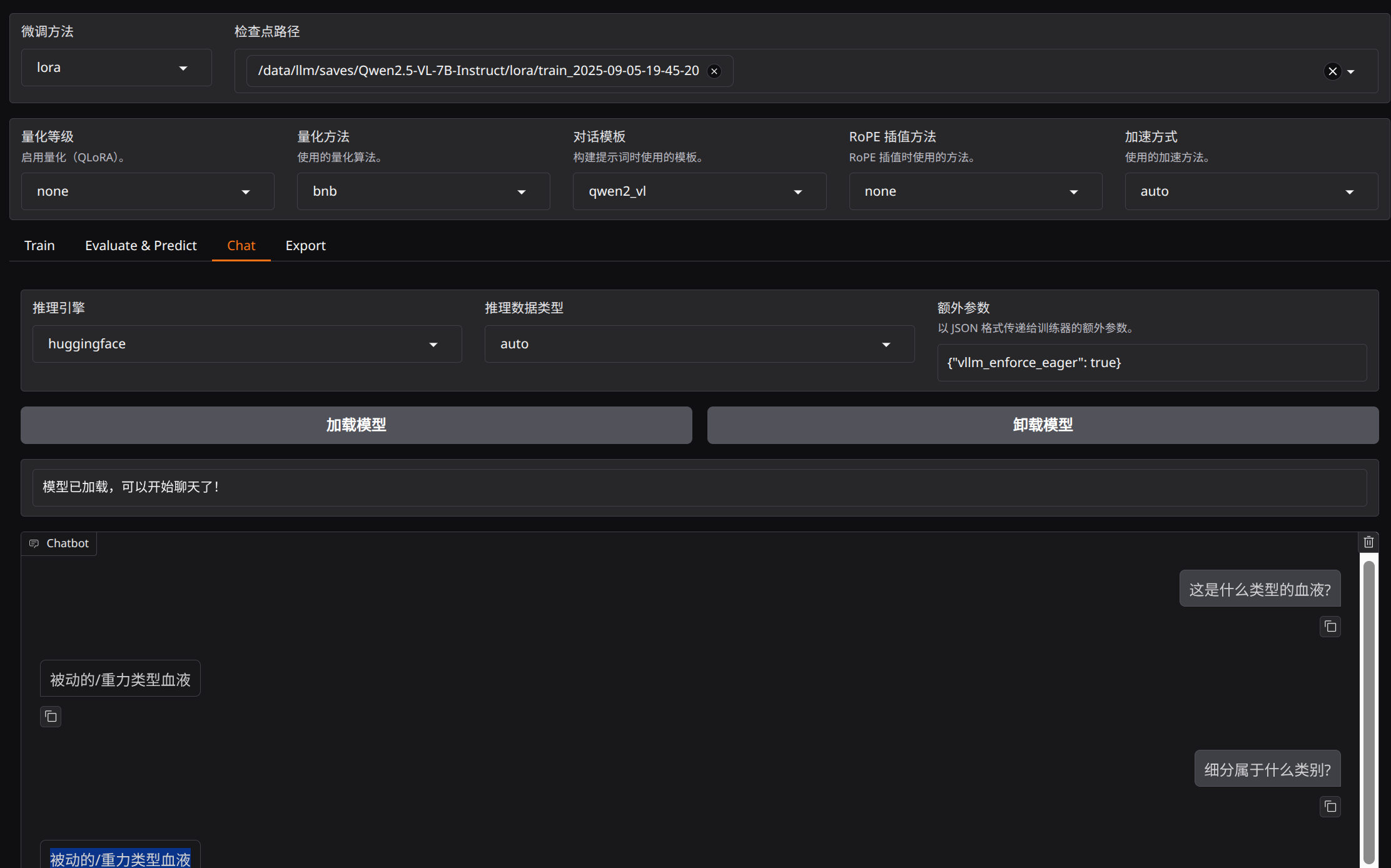
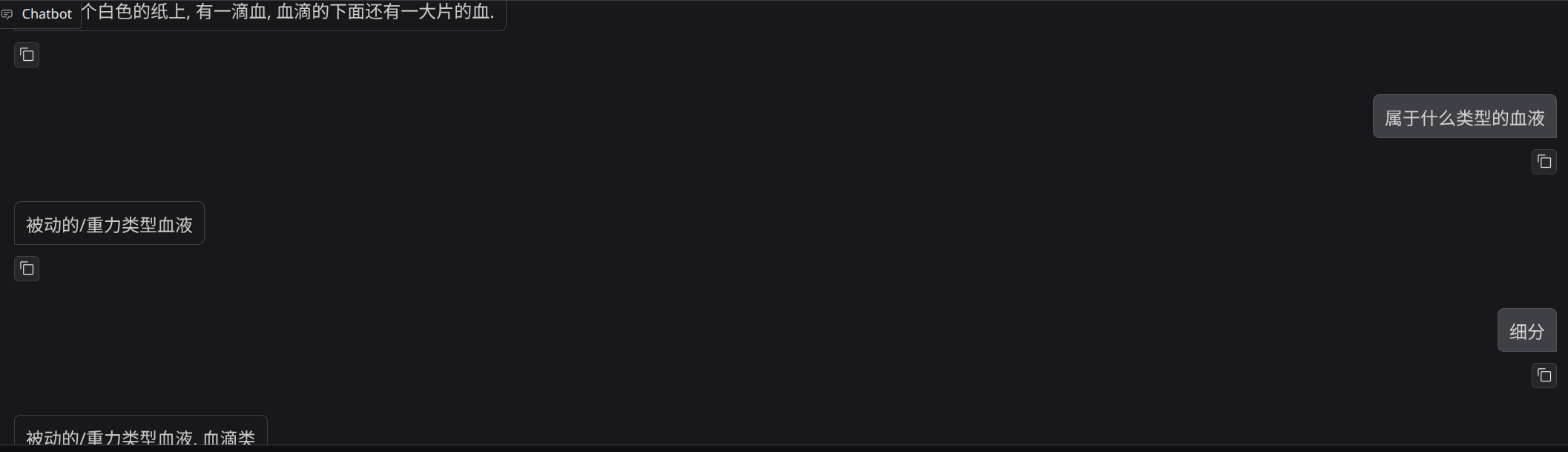
真正测试时,模型已经能识别出"被动的 / 重力类"这一层,但还不能稳定完成更细的分类。
1. 能识别的情况
比较容易区分的滴落型,已经有了一些正确识别:
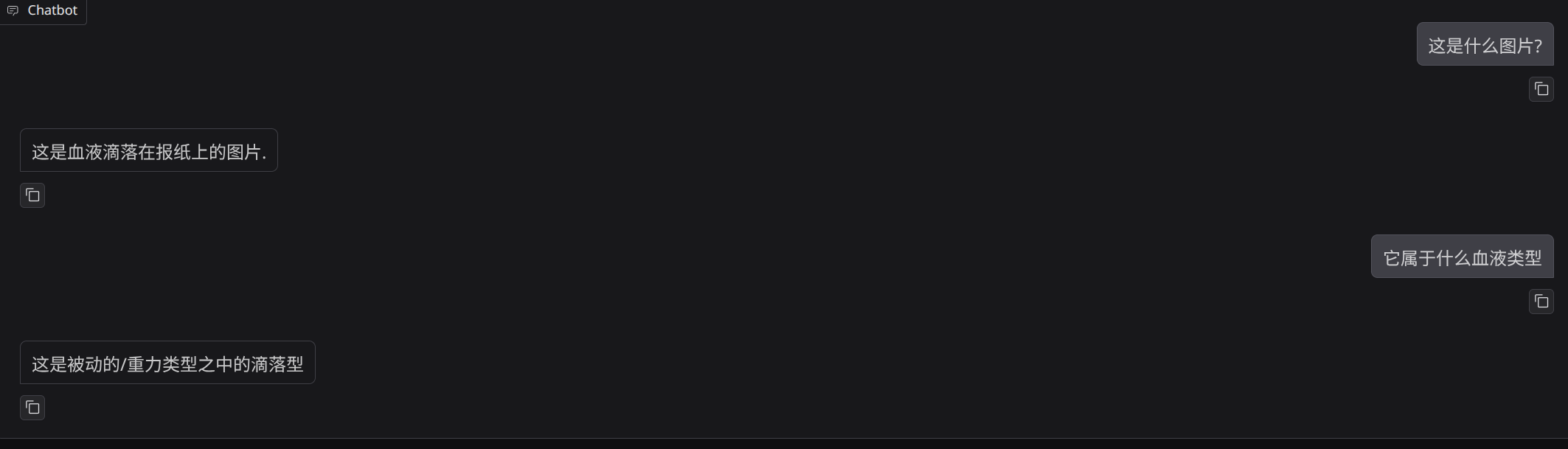
2. 还会混淆的情况
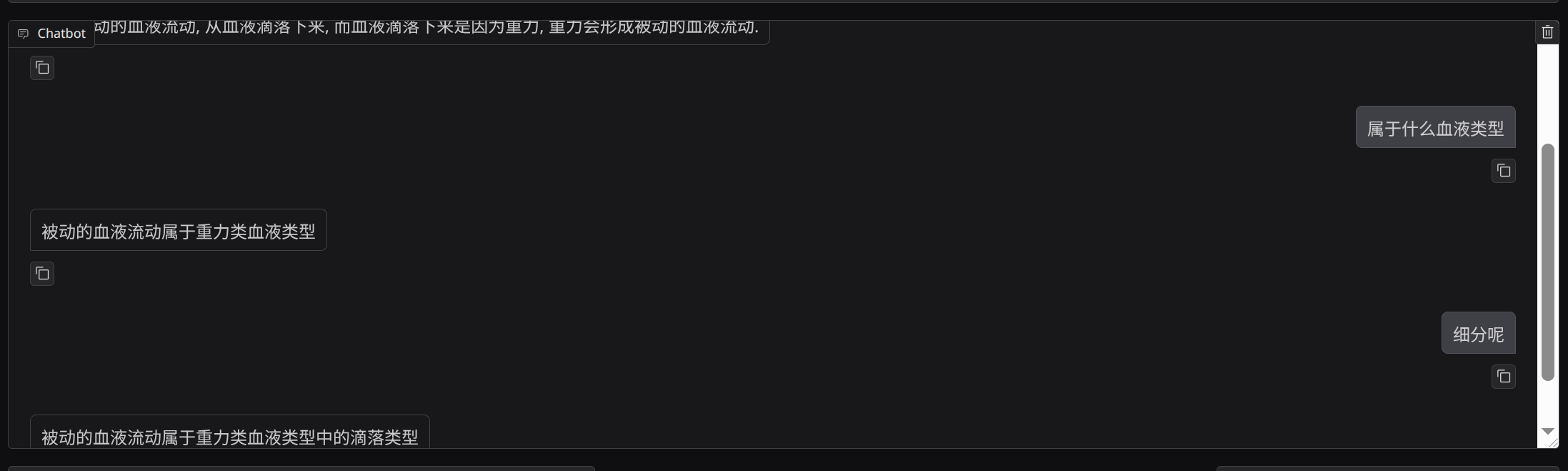
在不少样本上,它还是容易混淆类别,或者只回答到大类,不回答细分类:


对于接触类血液,也存在明显误判:
浸润 / 血泊型也会被误识别成滴落型:
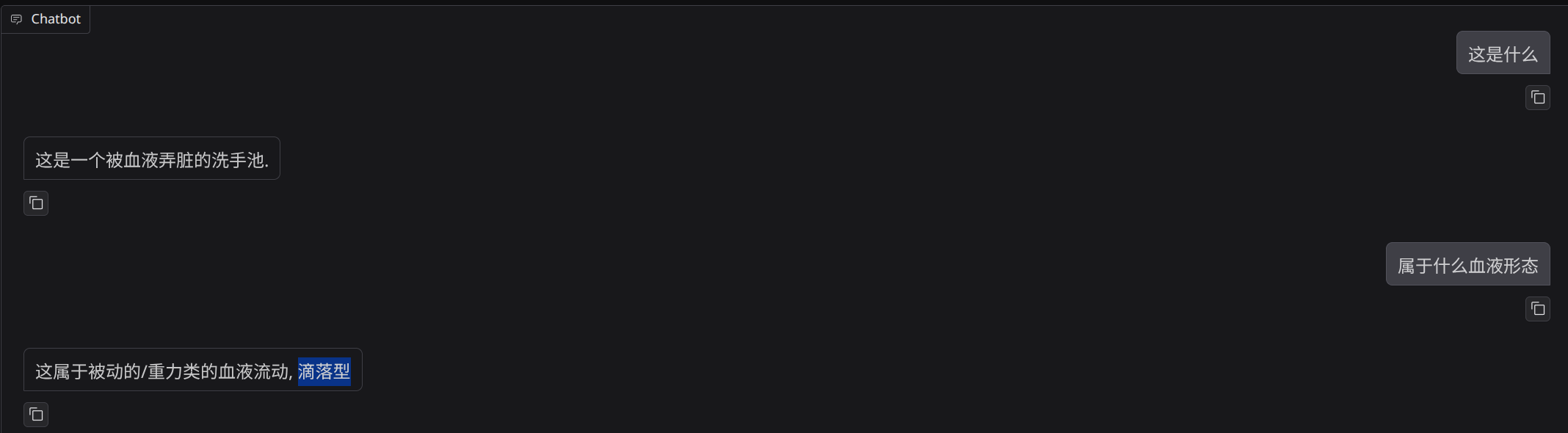
甚至在一些外部干扰明显的图片里,它还会先被背景带偏:

八、第一次实验最重要的价值
原笔记最后这段复盘其实特别像真实项目刚起步时的状态:
- 数据集太少
- Loss 虽然下降,但平滑程度一般
- 模型对任务边界感知不够
- 分类不够鲁棒,还会自行联想
- 回答过于简洁
- 类别分布不平衡,滴落型样本偏多
所以这次训练的真正结论不是"它不行",而是:
训练链路本身是合理的,问题主要暴露在数据设计与任务约束方式上。
这也是下一篇要处理的重点:
不只是"继续训",而是先把数据和提示方式重构一遍。
专题阅读
Fine Tuning
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。