
先回答 LoRA 为什么可行,再把 QLoRA 和 Qwen2.5-VL 放到同一条理解线上,最后落到几个真正会影响训练结果的超参数上。
这一篇对应原笔记里临时补上的 LoRA 理论部分。它的价值在于:把"LoRA 好用"从经验结论拉回到一个更能解释的层面。
一、LoRA 为什么可行
LoRA 的核心不是"神奇地省参数",而是它假设:
模型在适应一个新任务时,真正需要的有效权重变化,往往处于一个相对低维的子空间里。
也就是说,虽然原模型参数很多,但为了适应一个具体任务,未必需要对整个高维权重空间做全量自由调整。
1. 从矩阵低秩近似来理解
原笔记把这件事讲得很直观:矩阵的信息往往不是均匀分布的,很多维度冗余,主要信息集中在少数方向上。
如果一个权重矩阵 W 是 d × d,全量更新的参数量是 d²。
而如果把增量写成两个低秩矩阵的乘积:
ΔW = B × A其中:
B是d × rA是r × d
那参数量就从 d² 变成了 2dr。
只要 r << d,参数量会急剧下降。
2. 为什么更新量可以低秩
LoRA 论文的核心观察之一,是微调前后权重差值 ΔW 的主要信息往往集中在少数奇异值上。
换句话说:
- 预训练权重
W本身可能很复杂 - 但"为了适应新任务"产生的变化
ΔW,通常没有那么高的自由度
这就是 LoRA 低秩假设的经验基础。
二、LoRA 的训练过程
1. 初始化
LoRA 会冻结原始权重 W,只训练新增的低秩参数。
一般做法是:
W不动A用较小随机值初始化B初始化为 0
这样一开始 ΔW = 0,不会干扰原模型。
2. 更新
训练时,模型实际使用的是:
W' = W + ΔW = W + B × A前向传播时先得到预测结果,再根据损失函数对 A 和 B 做梯度更新,而 W 始终冻结。
3. 推理
训练后有两种常见方式:
- 合并 LoRA 权重后推理
- 保持 LoRA 旁路独立,按任务切换 adapter
这也是 LoRA 很适合多任务管理的原因之一。
三、LoRA 在 Transformer 里通常加在哪里
LoRA 常见的注入位置是:
- 注意力层里的
Wq / Wv - 前馈层里的升维 / 降维线性层
它不是任何位置都加,而是优先加在那些最能影响表示能力和生成行为的线性层上。
1. 常见示意图



2. 常见经验
- 小模型可以先只加注意力层
- 更复杂的生成任务,往往会扩展到 FFN
- 并不是参数越多越好,而是要看任务复杂度和数据规模
四、QLoRA 是怎么把门槛继续压低的
QLoRA 本质上就是:
- 先把基础模型量化到 4-bit
- 冻结这些量化权重
- 只训练 LoRA 参数
所以它不是"LoRA 的平替",而是:
量化 + LoRA 的组合方案
它最大的意义不是理论更漂亮,而是现实里真的能把显存需求拉下来,让更多单机环境也能做实验。
五、LoRA 的几个常用超参数
原笔记里对 LoRA 相关参数做了简要整理,这里直接沿着那条思路记:
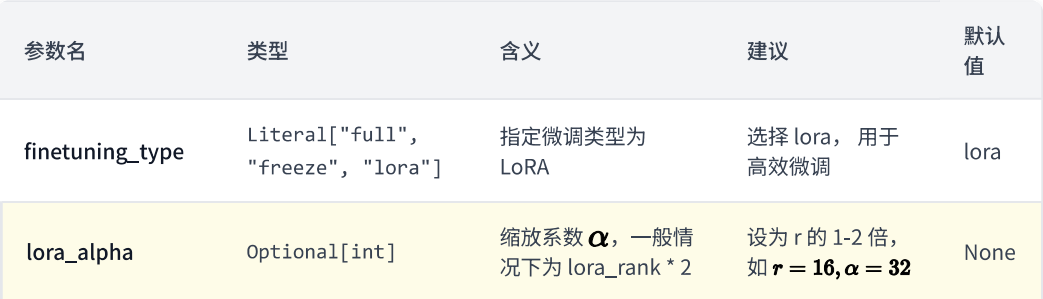
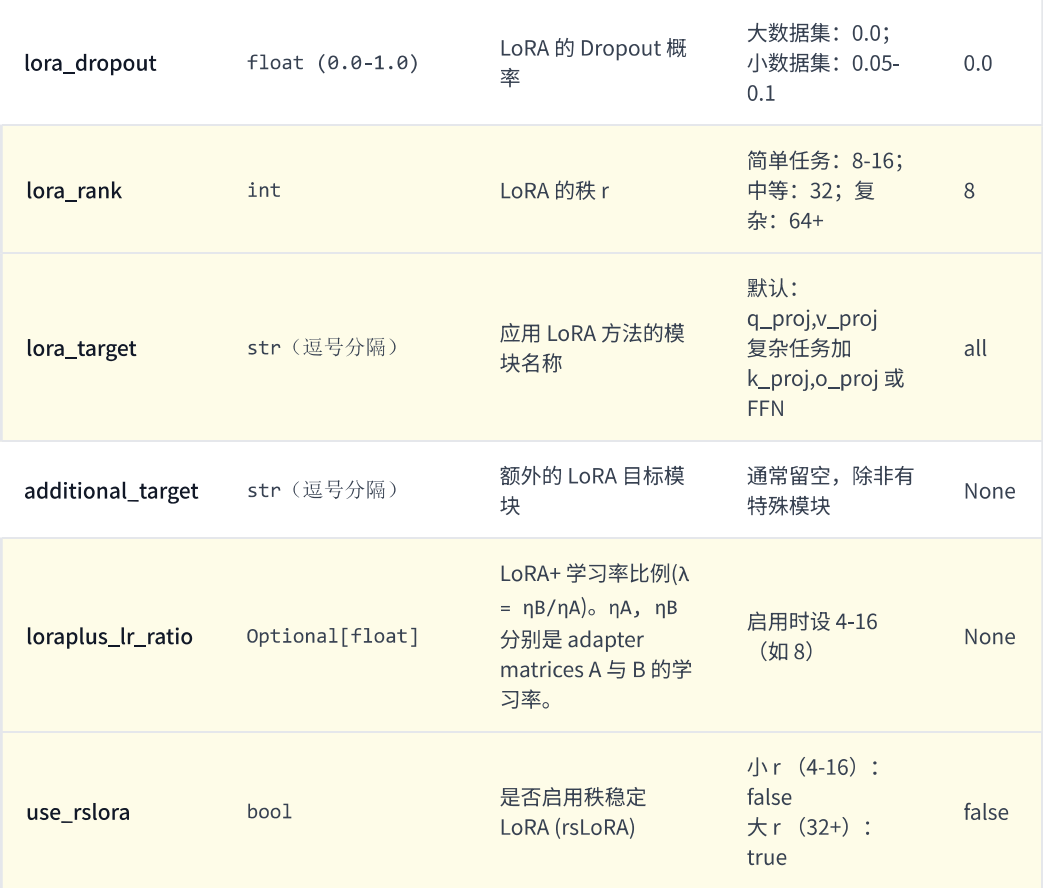
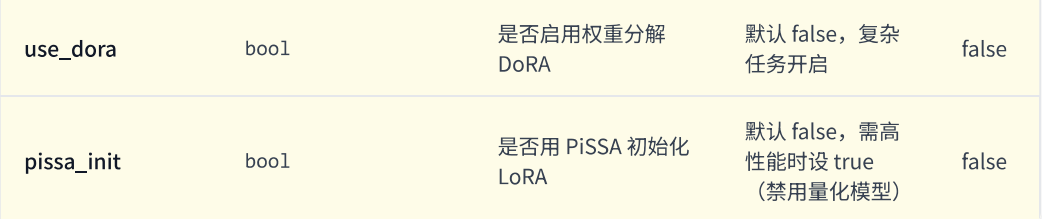
1. rank
rank 决定了低秩更新的表达能力。
- 小:参数更省,更新更保守
- 大:表达能力更强,但计算和显存开销更高
原笔记里的经验是:
- 小数据集先从
r=8或r=16开始 - 大数据集或更复杂任务,可以尝试
r=32+
2. alpha
alpha 可以理解成 LoRA 更新量的缩放系数,决定 LoRA 这条旁路影响原模型的强度。
3. dropout
dropout 更像是一点正则化,用来缓解小样本过拟合。
六、为什么这里顺手补 Qwen2.5-VL
因为这组实践最终就是做 Qwen2.5-VL 的多模态微调,所以如果对底座模型完全没有概念,后面的训练参数会显得很抽象。
Qwen2.5-VL 的特点可以先简单记成:
- 图像和视频是通过视觉编码器进入模型
- 视觉编码结果会和语言解码器对接
- 它对文档、表格、公式等复杂视觉内容也有比较强的建模能力
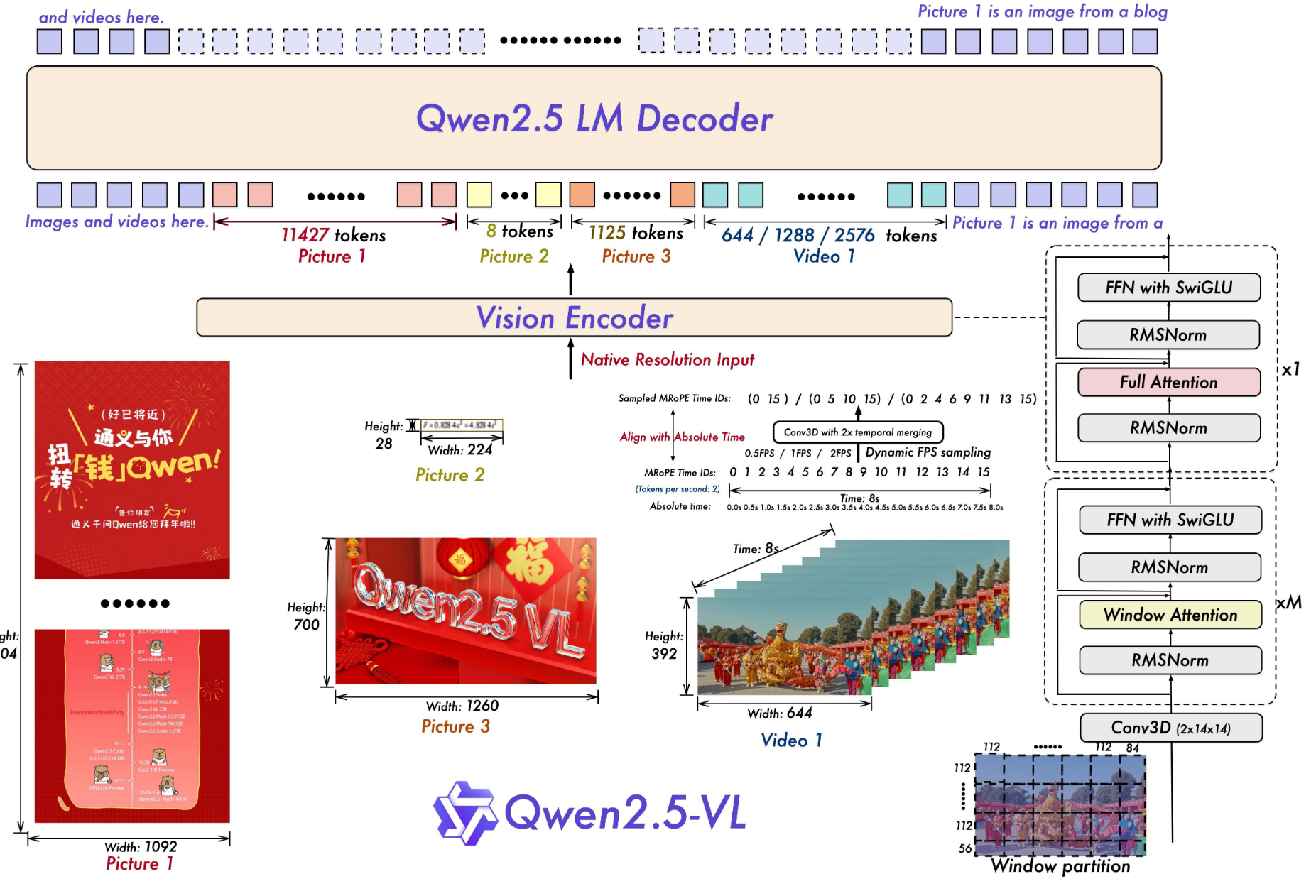
这也是为什么它适合后面那类"血迹图像描述 + 细粒度分类"的任务:
不是因为它天然懂这个领域,而是因为它作为多模态底座,已经具备了图像理解与文本生成的基础能力。
七、把理论留到一个足够实用的位置
学 LoRA 最容易掉进去的坑,是只记住"它省参数",但不知道它到底省在哪、为什么能省。
这篇最重要的目的,其实就是把后面实战里那些参数和结果,提前和一层理论对应上:
- 为什么 rank 选小了会保守
- 为什么小数据集更容易过拟合
- 为什么 QLoRA 会改变显存门槛
- 为什么底座模型能力仍然决定最终上限
专题阅读
Fine Tuning
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。