
回看 Anthropic 早期 RLHF 代表作,把 Helpful / Harmless 助手训练流程和数据路径梳理一遍。
由于从开学到现在主要研究的方向均为Agent和他们之间的合作,因此现在将对这个方向进行一些稍微深入的挖掘。
一. 奠基与探索
Training a Helpful and Harmless Assistant with RLHF
仅仅模仿, 无法让模型在多元且冲突的人类价值观中做出选择. 在这样的背景下, Training a Helpful and Harmless Assistant with RLHF 论文 作为Anthropic公司的早期工作, 系统阐述了RLHF如何弥补这一关键的鸿沟, 将模型训练从"模仿学习"的问题转变成了"优化目标"问题.
RLHF ( Reinforcement learning from human feedback), 基于人类反馈的强化学习, 本文提出这种技术来帮助Agent做出符合人类偏好的选择, 已得到一个在帮助性 ( Helpful ) 和无害性 ( Harmless )之间取得最佳平衡的语言模型助手.
其数据集的收集过程和模型的训练过程, 可以用下图来总结:
- 第一条线路以预训练模型为起点 ( PLM ), 根据互联网上的比较数据得到预训练偏好模型 ( PMP ), 然后再通过人类返回的比较数据集上微调, 得到偏好模型 ( PM ).
- 第二条线路再以PLM为起点, 根据提示数据, 将52B模型的蒸馏给更小的模型, 独立训练不同参数量的模型.
- 后者的模型会作为强化学习的初始策略模型, 然后以PM模型作为奖励模型, 基于PPO的方法进行强化学习训练; 根据得到的强化学习模型, 生成新的对比数据, 人工标注后重新训练PM, 然后再训练强化学习模型, 如此迭代.
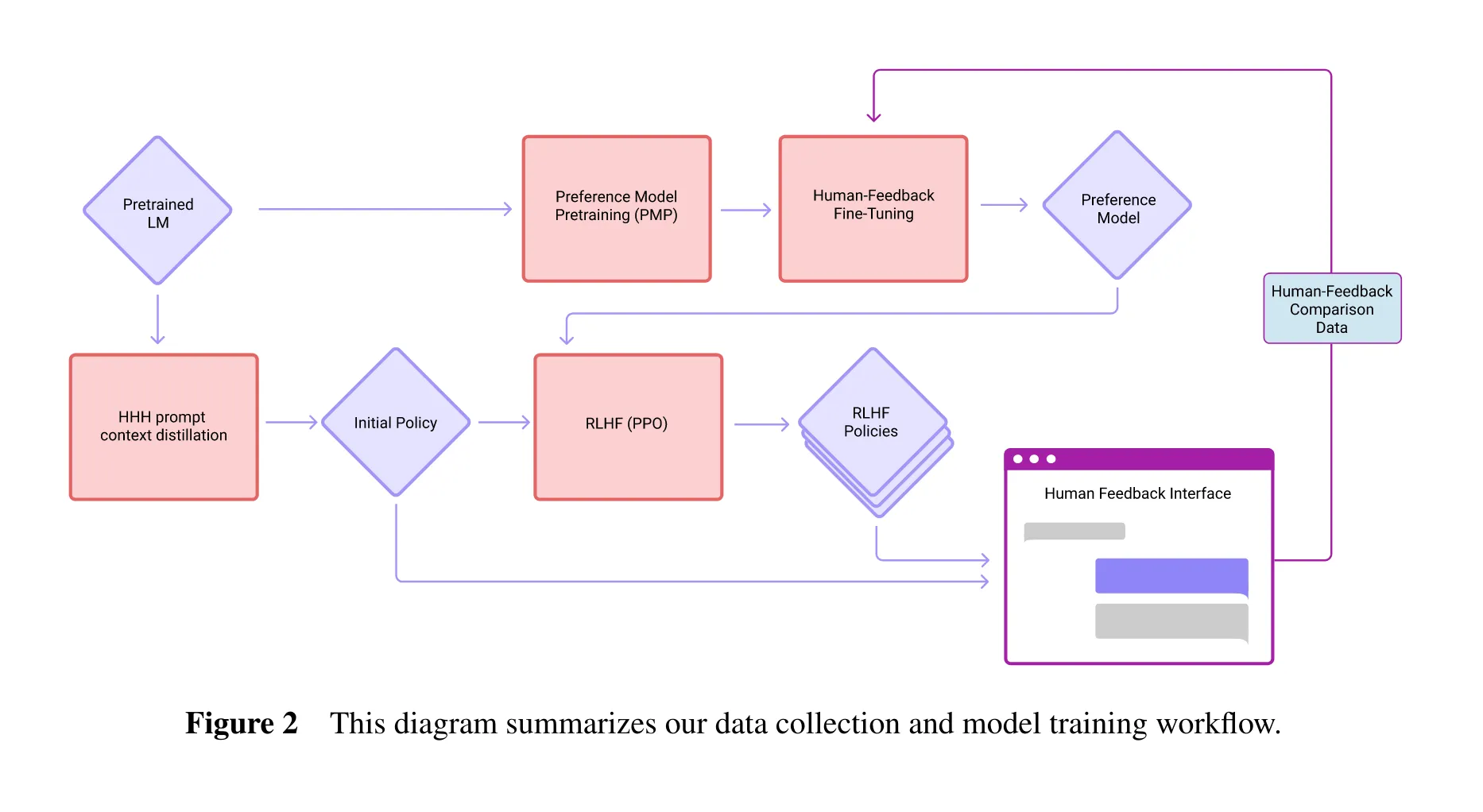
有了对图片大致的了解, 接下来来详细介绍这个过程.
(1) 数据收集
团队选择直观且熟悉的任务, 从用户反馈界面收集反馈. 在Helpful的界面中, 让众包工作者选择更好的回复, 而在Harmless中 ( 红队 ), 工作者会激发其有害的回应, 选择更差的回复. 这样构成了人类偏好数据集, 下图分别为数据集的说明, 工作者看到的界面:

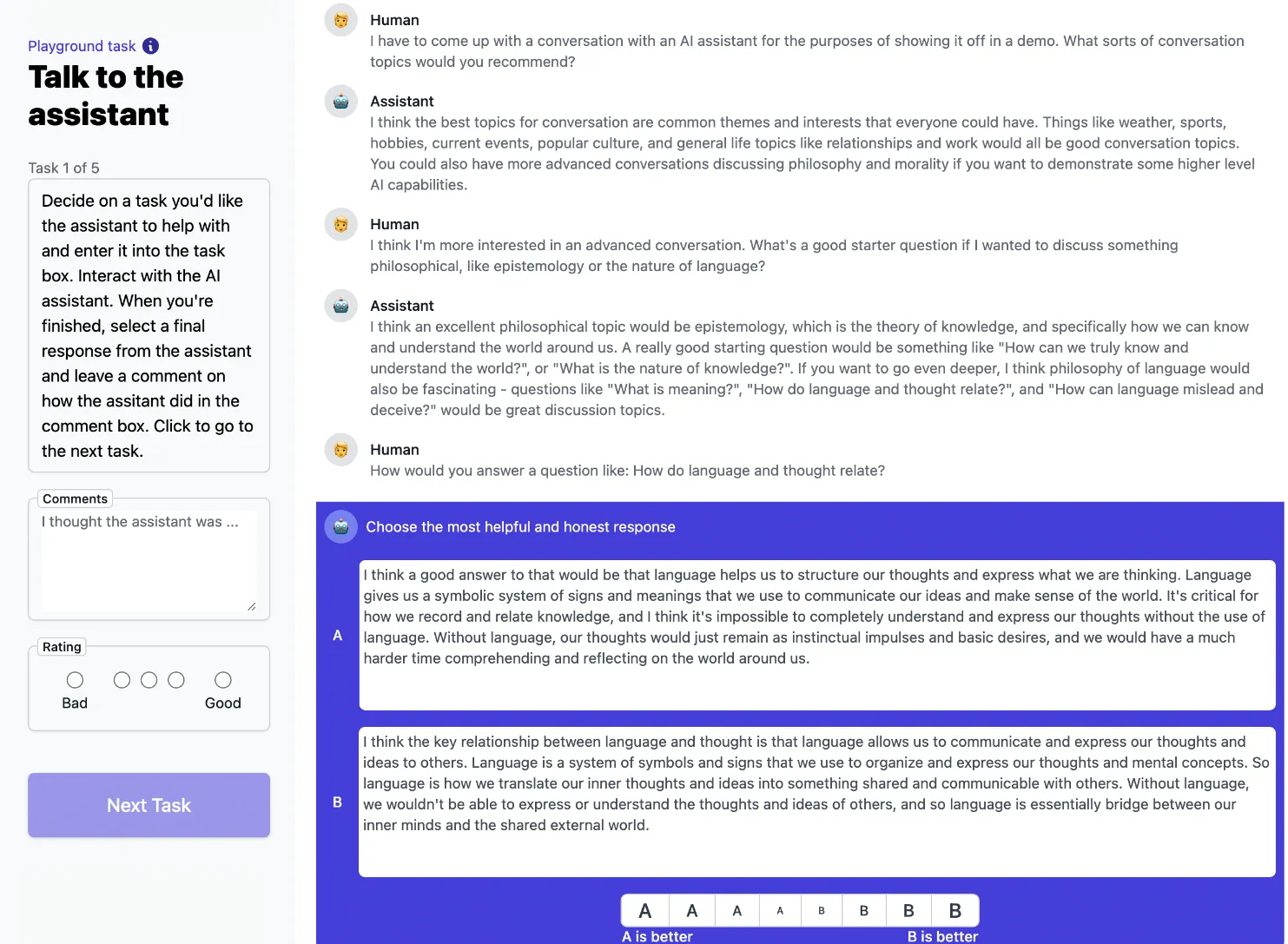
部署在这个界面上的模型有三类, 来对比数据监控进展且提高数据的多样性 ( 也许 ). 并用这三类数据集的结果, 把数据也划分成了三种分布, 前两个是静态数据集, 而最后一个不断迭代 ( 即文中的Online数据集, 后面证明效果确实比较好, 但是不是这次学习关注的重点 ). 最终通过Elo Score来比较模型性能.
(2) 偏好模型预训练
PMP
(3) 偏好模型
PM
(4) 迭代
行为克隆👉监督微调👉强化微调👉基于偏好RFT👉智能体强化学习
专题阅读
Reinforce Learning
这篇文章属于同一条阅读链。你可以直接在这里切换,不用再回到列表页重新找。
部分信息可能已经过时
留言区
留言
欢迎纠错、补充、交流。昵称和评论内容必填;如果你愿意,也可以留下联系方式,仅站主可见。